一.简介
公司服务器都是买的Dell,硬盘这些做了raid5+1.那么我们平时肯定要关注raid磁盘的健康状态,因为磁盘一旦超过2块坏掉,那么整个数据就不能恢复了。那我们怎么查看raid的健康状态呢?
Dell提供了一个OMSA的原生监控软件,可以来通过web界面查看服务器的raid相关运行状态.如下图:
登录界面: 用户名和密码就是Linux主机上的账号、密码
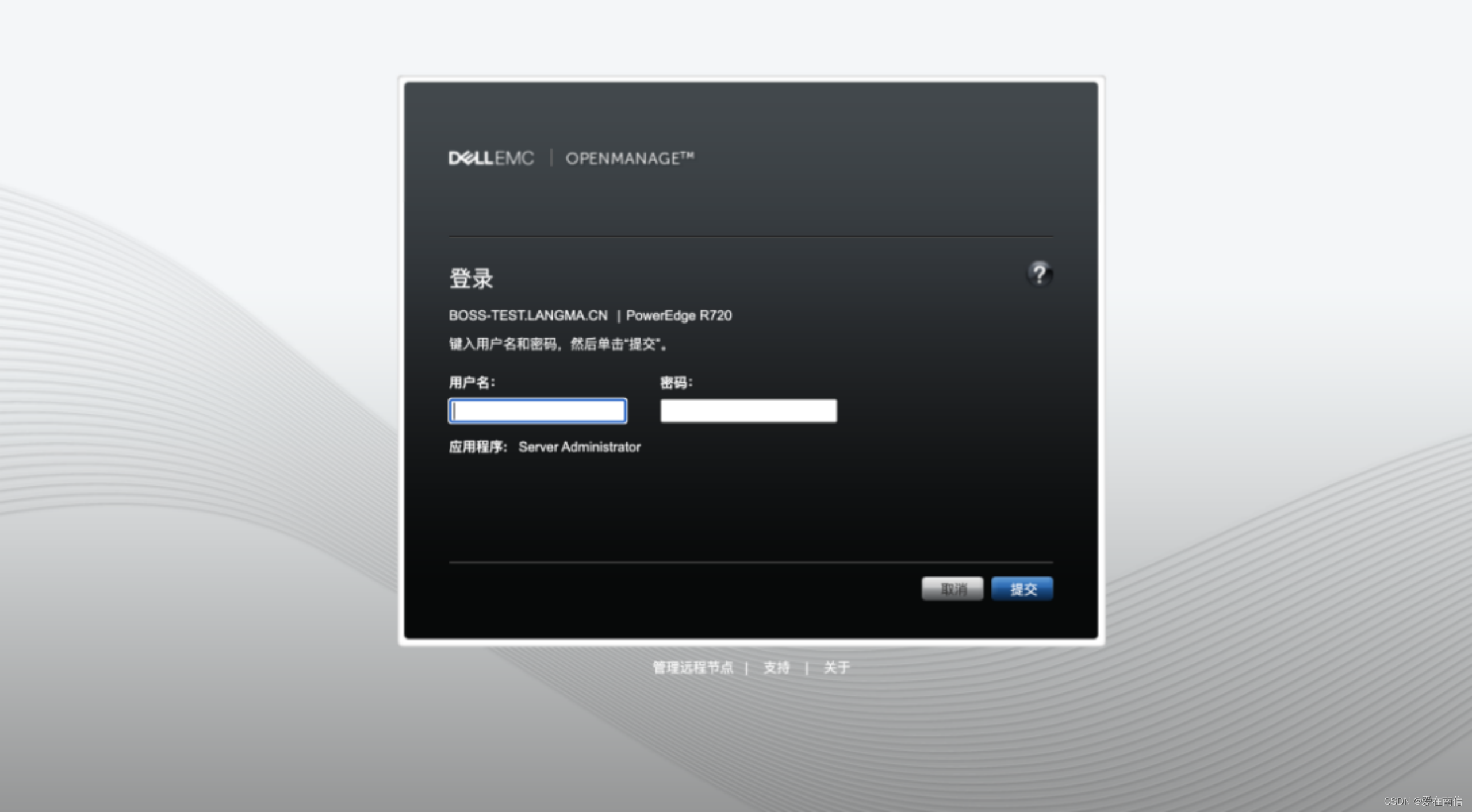
主页: 查看RAID硬盘健康状态,现在我们看到其实【磁盘位置:0:1:1】 有问题

但是这个OMSA监控软件有一个弊端就是:
不可以设置监控告警, 一旦硬盘有问题,那么及时通知我们收到告警信息,之后便于我们去更换坏的硬盘。
那么怎么办呢? 在我之前的运维同事做了一件我认为特别蠢并且比较无效的操作,那就是每隔一个星期去看下监控界面是否正常。 我的乖, 有几台服务器我就不说了, 搞个几十台上百台服务器,你能看得过来吗? 低效不说,浪费时间去做这个事情,没什么意义,及时性也得不到保障。
二.结合Promtheus
1.监控Grafana界面
监控平台由之前的Zabbix被我牵头迁移成为Prometheus体系,那么我自然想到把所有相关运维监控,告警等都融合到这个体系里面去,能做到统一。
那首先我自然想到是否有人做了这个Dell OMSA的exporter, 如果有的话,那么我每台服务器部署一个exporter, 加入监控,再配置告警不就万事大吉了?
说干就干, github上搜索omsa exporter.还真被我找到了一个外国哥们写的exporter:
项目地址: https://github.com/galexrt/dellhw_exporter
这个项目原理其实就是执行OMSA的可执行命令,查看RAID状态,然后暴露exporter信息而已.
OK.部署好exporter之后,我们看下监控界面:
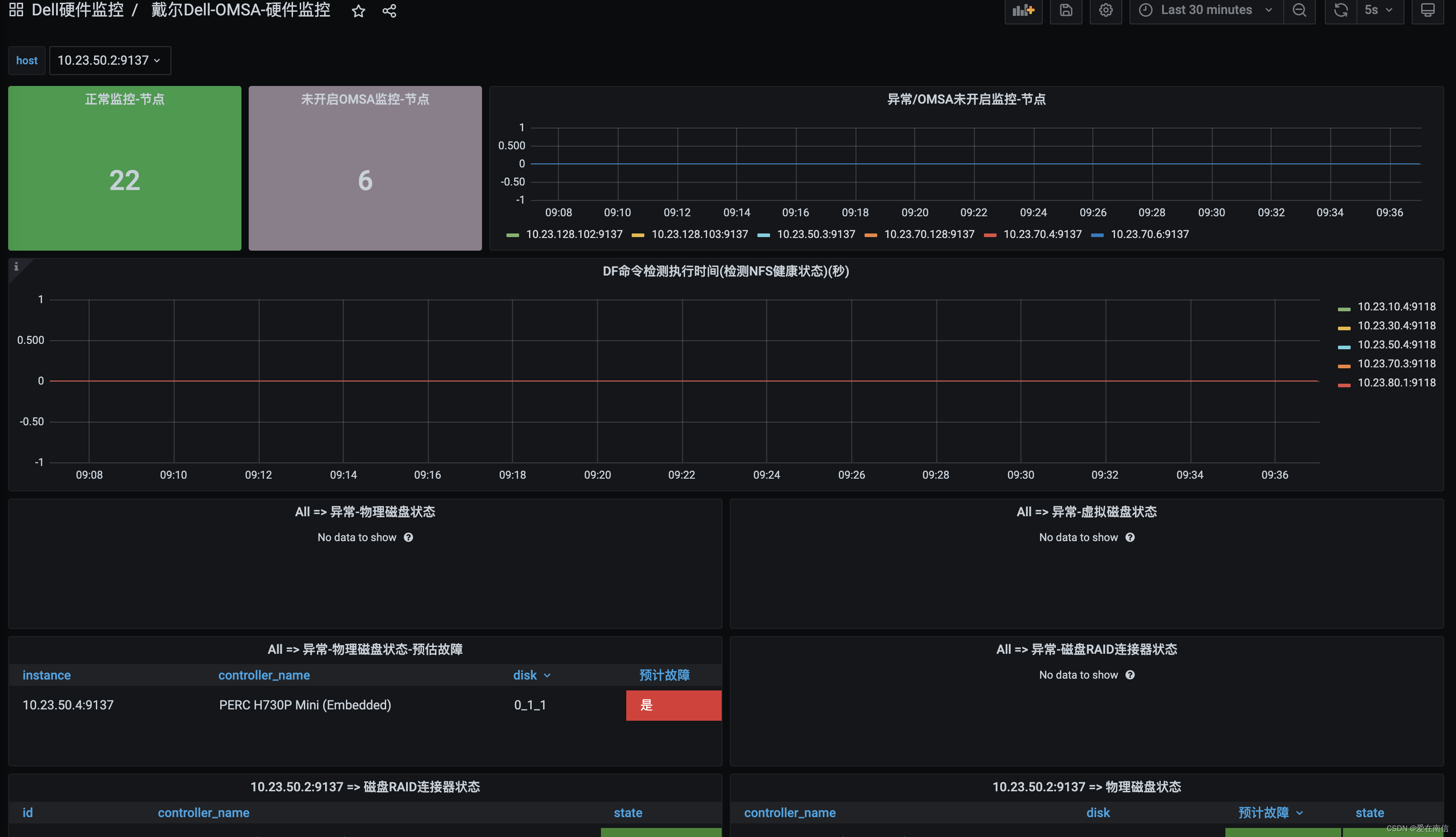
这个是我绘制的Grafana看板: https://grafana.com/grafana/dashboards/15839-dell-omsa/
正如Grafana看板显示【磁盘 0:1:1】出现了问题和OMSA后台界面信息一致.
2.告警与配置
已经能配置Promethues,那么告警配置我就不赘述了.直接上rule yaml配置关键内容, 大家主要关心的是omsa exporter的哪些metrics指标的意思,大家可以看下那个项目的官网结合OMSA的指标信息进行关联.
1 | groups: |
我把告警信息推送到了钉钉:

从此之后妈妈再也不担心我的磁盘健康问题,有问题收到告警,联系机房人员更换即可.
三.OMSA 10.1 不支持高版本服务器型号(R750等)问题
OMSA 10.1 不支持R750的服务器型号,但是10.2版本和10.3版本支持R750型号, 但是你会发现一个奇怪的问题.Dell官网死活找不到10.2和10.3的下载链接痕迹, YUM的rpm包也不提供,那坑底了,之前我3个月磁盘监控都是裸奔的,完全不知道磁盘健康状态。 后来专门打电话问了戴尔技术客服才解决这个问题,给大家排个坑, 访问下面的链接下载10.2版本的安装包即可:
访问链接: https://www.dell.com/support/home/zh-cn/drivers/driversdetails?driverid=f6m31
点击下载对应操作系统的包即可:
安装教程: