The post Choosing the Right Cloud Provider: Key Factors for a Strategic Decision appeared first on SHALB.
]]>
While many enterprises today adopt a multi-cloud strategy to avoid vendor lock-in and reduce costs, Gartner suggests it is impractical for most IT teams to fully manage more than one or two cloud platforms. This makes choosing a cloud provider a highly strategic decision that will significantly influence a company’s operations for years to come.
In this article, we’ll highlight the key factors to consider when choosing the right cloud service provider.
Identify things to influence your choice
Today, choosing a cloud provider goes beyond evaluating their technical capabilities. It’s about selecting a long-term partner who can effectively support your company’s goals on its cloud journey. Before moving forward, it’s crucial to identify key questions that will guide your decision. A clear understanding of these factors will help you make the right choice.
- What is your strategic business goal? First and foremost, it’s essential to understand why you’re moving to the cloud. What will this step bring to your organization, and what challenges will it help resolve? Perhaps you aim to expand your business, but technical limitations of your current infrastructure are holding you back. Or maybe you want to ensure uninterrupted services and improve response times.
- What data do you plan to store in the cloud, and how frequently will it be accessed? This information is critical for selecting the right storage class. Depending on your data usage and workload, a hybrid model – keeping some data on-premises – might be more suitable. Consider the type of data you’ll store: could migrating it affect compliance?
- What functions are you planning to delegate to a provider? You may want to shift from self-hosted to managed services to relieve your team from tasks like updating and patching, freeing them to focus on core priorities.
- What budget have you allocated for cloud services? Cloud billing can be complex, with some services dependent on others for proper function. This setup often leads to unintended cloud sprawl, driving up costs. Knowing your budget and understanding the billing model is essential to avoid surprises.
Key factors to consider when choosing the right CSP
Technology Base and Service Offerings
According to Gartner, one of the primary reasons companies move to the cloud is to upgrade their technology base. So, ensure that your chosen CSP offers an innovative technological platform with a range of services that align with your business needs. Leveraging specialized cloud services to perform specific tasks can greatly improve your application efficiency. For instance, serverless computing is ideal for applications that handle periodic events without needing constant uptime, like processing transactions after purchases or verifying user identities when accessing the platform.
A key consideration here is whether your applications are compatible with the provider’s technologies. Older legacy systems may need substantial rearchitecting before migration to ensure smooth integration. This may require refactoring your application to fit its new environment—or even replacing it with commercial software delivered as a service (SaaS).
Ensure your CSP can support you through the migration, as it’s a technically complex process that may exceed your team’s expertise.
Security
Security is a critical factor when choosing a cloud provider. Look closely at the provider’s data and system security measures, and assess the maturity of their Cloud Security and Compliance Management processes. Be sure to review the provider’s certifications to ensure they meet industry standards and are up-to-date.
Remember that cloud security is always a shared responsibility between the provider and the customer. The division of responsibility depends on the cloud service model in use:
- IaaS environments: The CSP manages the underlying hardware – servers and storage – ensuring security patches and updates are applied. Customers are responsible for managing the OS, runtime, scaling, and all data.
- PaaS environments: The CSP covers runtime, server management, scaling, operating systems, and virtualization. Customers remain responsible for securing their own code and its deployment.
- SaaS environments: Fully managed applications are maintained and secured by the cloud provider, while customers are responsible for securing their own data.
Major cloud providers like Azure, AWS, and Google offer a range of essential security tools as part of their service offerings, and it’s highly recommended to make full use of them if you’re in the cloud. For instance, in AWS, you can leverage tools like WAF and Shield to protect against Distributed Denial of Service (DDoS) attacks, CloudTrail for auditing activities, and GuardDuty to gain visibility into anomalies across different parts of your account.
Availability & SLA
A core expectation for any CSP is their ability to deliver uninterrupted service. A provider’s commitments to your applications’ availability are defined in the Service Level Agreement (SLA). Essentially, an SLA represents the provider’s guarantee of your application’s uptime, even in the event of an outage on their end. For example, an SLA of 99.97% availability implies that potential downtime due to provider-related issues is limited to 0.03%, which translates to roughly 2 hours and 37 minutes per year. Leading cloud providers typically offer SLAs of no less than 99.9%.
The greater the provider’s geographic reach, the closer data storage can be to end-users, reducing latency and enhancing response times—an essential factor for critical services.
Hyperscalers compete heavily on regional coverage, with Azure leading at over 60 announced regions and 140 availability zones, followed by AWS with 108 zones across 34 regions, and Google Cloud Platform (GCP) offering more than 40 regions and 121 zones globally.
Scalability
Scalability is a key cloud feature that ensures your application’s business logic runs smoothly, even during peak traffic hours. A reliable cloud provider should be able to scale alongside your business, allowing you to add new cloud resources whenever needed.
While each cloud provider has its own scaling mechanisms and configurations, the main goal remains the same: to ensure stable, predictable application performance, even as traffic grows. This is achieved by organizing resources into scaling groups, allowing them to be managed as a single unit. Tools like AWS Auto Scaling in AWS or Compute Engine in GCP monitor resource usage and automatically adjust capacity in real-time as demand shifts. Autoscaling can be configured based on factors like CPU utilization, load balancing capacity, monitoring metrics, or pre-set schedules.
Certification
Certifications confirm the level of data security and confidentiality that a CSP guarantees to customers. They also reflect the provider’s commitment to industry best practices, service quality, and reputation. While certifications alone may not be the deciding factor, they help narrow down providers that meet your company’s regulatory requirements and industry-specific needs.
There are both international and region-specific standards, such as HDS Certification in France, required for CSPs hosting health data, or the General Data Protection Regulation (GDPR) in Europe, which sets rules for handling personal information of EU citizens.
Some well-known international standards include:
- ISO 27001 – Sets requirements for information security management systems, focusing on handling sensitive data.
- ISO 27017 – Verifies the provider’s commitments to technical, legal, and organizational security measures.
- ISO/IEC 27018:2019 – A code of practice for protecting personally identifiable information (PII) in public clouds.
- HIPAA – Similar to HDS Certification, regulates the confidentiality and security of patient data.
Resilience
There are several ways to evaluate a service provider’s reliability.
Start by reviewing the provider’s SLA performance for the past 6–12 months. Some providers publish this information, while others can provide it upon request.
Remember that occasional downtime is unavoidable for any cloud provider. What matters most is how they handle these incidents. Make sure their monitoring and reporting tools are sufficient and compatible with your overall management and reporting systems.
Check that the provider has well-documented and proven processes in place to handle both planned and unplanned downtime. They should have clear communication protocols for keeping customers informed during disruptions, including how they prioritize issues, assess severity, and communicate timely updates.
Finally, understand the remedies and liability limits that the provider offers in case of service disruptions.
Conclusion
Choosing a cloud service provider is a complex decision that extends beyond simply comparing pricing quotes. Given its significant impact on business operations, this choice should be made after a thorough technical evaluation and in close collaboration with your technical team.
If your IT team needs additional support, consult with professionals. SHALB certified cloud architects can recommend the infrastructure and services best suited to your project needs. We work with leading cloud providers, including Amazon Web Services, Google Cloud Platform, Microsoft Azure, DigitalOcean, and IBM Cloud. Contact us to get the most out of cloud computing with SHALB cloud infrastructure design services.
The post Choosing the Right Cloud Provider: Key Factors for a Strategic Decision appeared first on SHALB.
]]>The post Enhancing Container Security: Signed and Encrypted Images appeared first on SHALB.
]]>
However, containers, which are replicas of their parent images, also inherit any vulnerabilities or misconfigurations present in those images. This makes container security a critical part of the overall software supply chain. In this article, we’ll explore the role of digital image signing in protecting containers from tampering and man-in-the-middle attacks.
Why is image signing important?
Before we proceed to the main part, let’s briefly revisit what a container image is.
An image is a bundle that contains everything a container needs to run: code, binaries, and libraries. It is immutable, meaning it cannot be altered—any necessary changes require the creation of a new image.
Images are built in layers, with each layer representing a set of file system changes, such as adding, removing, or modifying files. These layers combine to form the container’s complete filesystem. Any configuration settings specific to the container can be applied as additional layers.
Pre-built images are often uploaded to public registries for users to access. However, unsigned images are essentially a black box – it’s difficult to verify what they contain. A cryptographic signature – an encrypted data hash – ensures that the image is exactly what it claims to be: an authentic product as intended by its creator. The signature adds an extra layer of security, guaranteeing:
- Authenticity: Confirming that images come from a trusted source and remain untampered.
- Integrity: Guaranteeing that images have not been changed during transfer or storage, protecting systems from threats like image poisoning.
- Freshness: Verifying that images are up-to-date with the latest security patches, preventing attackers from exploiting outdated or insecure versions.
Images can be signed by developers, organizations, or automated systems, such as a CI/CD pipeline configured to sign built images.
How to verify image legitimacy?
To ensure the legitimacy of an image, you need to validate both its integrity and its provenance from trusted sources. Hashing, also known as a digest, is used to verify the integrity of the image.
Digest
A digest is a cryptographic fingerprint of an image, recorded in its manifest file. The container engine calculates the final image digest by hashing the manifest, which includes the hashes of all image layers. The SHA256 algorithm is used for hashing, generating a unique 32-byte signature based on the image’s content. Any changes to the image or its layers will produce a different digest, indicating a mismatch with the original.
Digital signature
Image signing confirms the image’s origin and creator. Images can be signed using offline keys or through a keyless method.
Signing with offline keys
Cryptographic signatures rely on asymmetric encryption, a method that uses two keys: a private key, which remains confidential, and a public key, which is shared with others. To create a digital signature, the signer first hashes the original image using a hashing algorithm and then signs the resulting hash with their private key. The signed hash, along with the original image and digital certificate, is bundled and uploaded to a registry. This allows consumers to retrieve the signature at any time to verify the publisher’s identity.
On the client side, the consumer hashes the original image using the same algorithm, generating a hash for comparison. Next, they use the public key from the digital certificate to decrypt the signed hash and obtain the original image’s hash. If the two hash values match, the image is verified; any discrepancy indicates that the image has been altered.
Figure 1 illustrates a simplified overview of how image signing works:
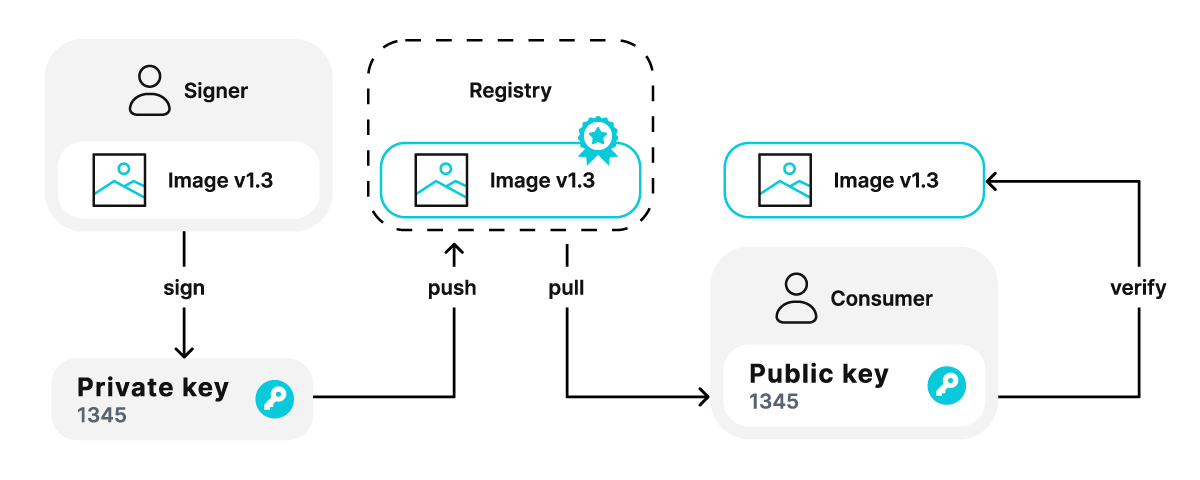
Figure 1. Signing with offline keys involves using a private/public key pair to verify the authenticity of a container image.
Keeping your private key secure should be a top priority, as it is essential for maintaining control over your system. If the private key is compromised, malicious actors could create signatures that appear to be yours and use them to sign tampered images. Best practices include using hardware security modules (HSMs) or trusted platform modules (TPMs) for on-premises environments, and Key Management Services (KMS) in cloud environments. These technologies serve as secure vaults, offering strong protection against potential breaches.
Keyless signing
This method uses ephemeral keys and short-lived certificates, valid only at the time of signing. The keys are retained until the image is signed, after which they are discarded. Each signature requires a new certificate from the Certificate Authority, as certificates are single-use. Details about the signature are recorded in a transparency log, an append-only, tamper-resistant data store.
When data is added to the log, the log operator provides a signed receipt, which serves as proof that the data is recorded. The log can be monitored for any unusual activity. The transparency log receipt can be included with the signature as further evidence of its validity.
Verifying signer’s identity
To trust the image, the verifier must check both the signature and the identity of the key pair owner. This identification is achieved through certification that links a specific subject to the signature. The certificate is issued by a Certificate Authority (CA), which verifies the signer’s identity based on the information from one of OpenID Connect (OIDC) providers such as Google, GitHub, or Microsoft.
One key factor to consider is the expiration of certificates. Usually, certificates are no longer trusted once they have expired, meaning that image signatures are only valid up until the certificate’s expiration. Since images often need to last longer than the certificate, having a short-lived signature is not good.
This issue can be addressed by using a Timestamp Authority (TSA). A TSA receives the data, combines it with the current timestamp, and signs the bundle before sending it back. By using a TSA, anyone who trusts the authority can confirm that the data existed at the specified time.
Figure 2 illustrates main steps of the process of verifying a signer’s identity:
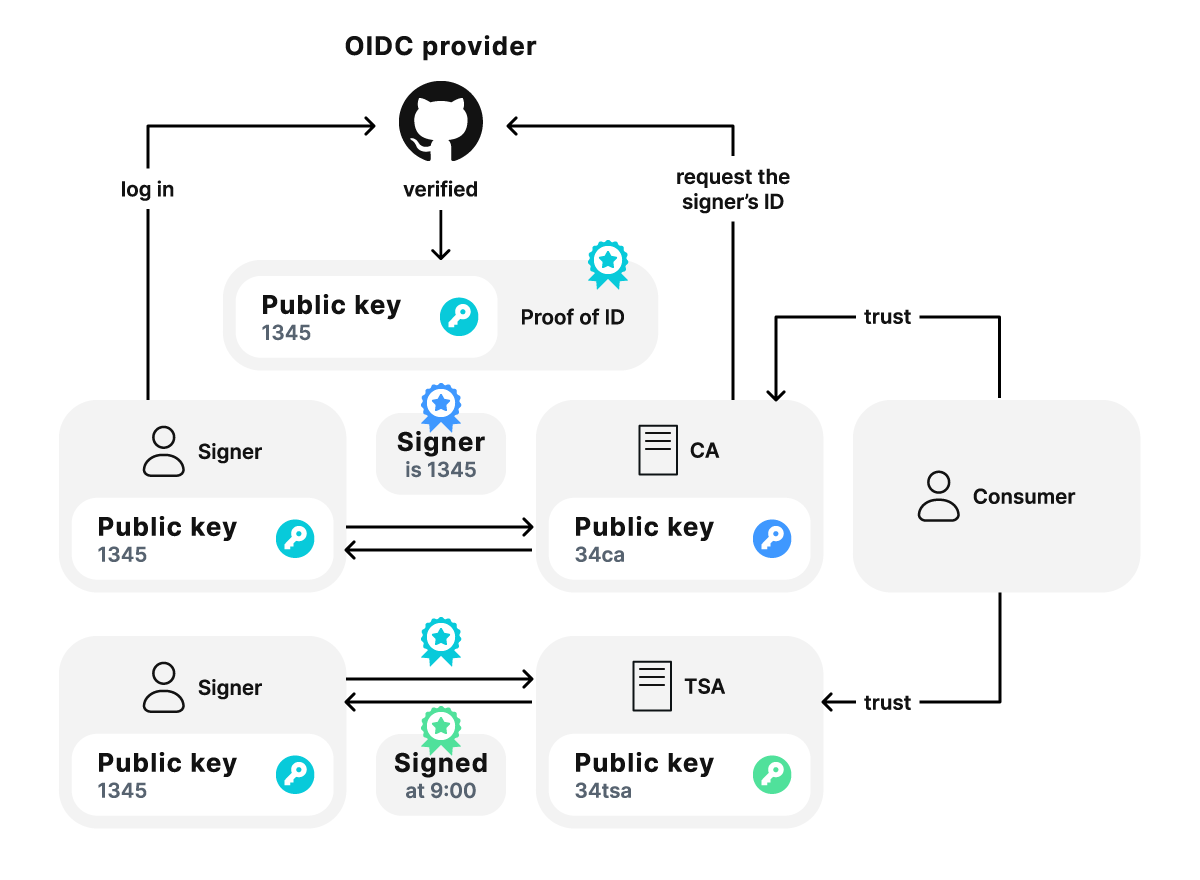
Figure 2. Trust policy for verifying the signer’s identity is based on information obtained from an OIDC provider, a Certificate Authority, and a Timestamp Authority.
Image signing technologies
The Update Framework
Popular image signing tools, such as Notary and Cosign, rely on The Update Framework (TUF) as a root of trust – a foundational security component to verify the validity of signing material.
TUF is a security framework designed to protect software update systems from a variety of attacks, such as replay attacks, targeted attacks, and man-in-the-middle attacks. By operating a set of protocols, TUF verifies the authenticity of the update file. In the context of image signing, TUF provides additional layers of security, including:
- Key protection: Rather than relying on a single root key, TUF recommends creating a set of root keys distributed across different systems. A quorum of these keys is used to sign the operational keys that are used daily. These signing keys are then rotated on a regular schedule to enhance security.
- Role delegation: TUF allows for delegating trust to different roles, which can sign and validate container images.
- Versioning and Expiration: TUF can help prevent the use of outdated or compromised images by enforcing strict version control and setting expiration dates on images and metadata.
Docker Content Trust
Docker Content Trust (DCT) is a Docker-native framework for signing images. Built on the Notary Project, it implements key principles from the TUF specification to verify both the integrity of images and the identity of their signers. In DCT, an offline root key is used to generate repository keys for signing image tags. Additionally, a server-managed timestamp key is applied to signed images, ensuring freshness and security for your repository.
Cosign
Cosign is an open-source project by Sigstore, created for signing, verifying, and storing artifacts in OCI repositories. It supports signing methods using both long-lived keys and ephemeral keys.
In keyless signing, Cosign generates ephemeral keys and certificates, which are automatically signed by the Fulcio root certificate authority. Fulcio authenticates the signer’s identity using their OIDC token. The signatures are then stored in the Rekor transparency log, which provides an attestation at the time of creation.
Main take-aways
The importance of images in deploying containerized applications makes image signing critical to overall supply chain security. Ultimately, container image signing involves:
- The creator’s cryptographic signature applied to the image.
- A cryptographic hash, unique to each image, that verifies the image’s authenticity and integrity.
- A signing certificate, often issued by a trusted certificate authority (CA), which includes the public key and confirms the approval of the signing process.
- A private key, securely held by the image creator, used to sign the image and ensure it remains confidential.
Resources
Container Images: Architecture and Best Practices
Container Image Signing: Why and How
Signing Docker Official Images Using OpenPubkey
Container Image Signing: A Practical Guide
What Are Docker Image Layers and How Do They Work?
Signing container images: Comparing Sigstore, Notary, and Docker Content Trust
The post Enhancing Container Security: Signed and Encrypted Images appeared first on SHALB.
]]>The post From Trust to Expertise: How to Choose the Best DevOps as a Service Partner appeared first on SHALB.
]]>
Outsourcing involves delegating tasks or projects to an external team that completes the work independently. This business model ensures efficiency, quality, and timely delivery. In contrast, outstaffing – a type of remote recruiting model – might be more cost-effective in the long run, but it leaves the employer dealing with the human factor, being responsible for the productivity and work pace of the outstaffed workers. Outsourcing, on the other hand, frees you from managing and controlling the project workflow, delivering just the final result.
So, what key factors should you consider to ensure you make the right choice?
Trust
When choosing a DevOps as a Service company, it’s ideal to rely on recommendations. If you don’t have this option, assess the company’s experience. How long have they been in the market? Review their portfolio of completed projects, especially those in the same sector as yours. This is particularly important in sectors like fintech and banking, where strict security regulations can significantly limit or even deny the provider access to the production environment during development. If they have relevant projects, case studies detailing the implementation can be invaluable.
A company’s reputation is a strong indicator of whether you can trust them, especially regarding data security, due diligence, and business practices. A key marker of trustworthiness is the company’s longevity in the market—if they meddled with customer data or caused some significant business disruptions, they likely wouldn’t have survived long.
Expertise
When engaging a third-party contractor, one of the primary concerns is their expertise: do they have the right skills? Can they truly deliver? The best way to verify this is by organizing a meeting between your technical team and theirs. It’s highly advisable to include the principal engineer or the technical lead who will be in charge of your project. This will help you determine two things: 1) whether the provider’s team has the necessary skills to deliver the project, and 2) whether your teams can communicate effectively and work well together—an essential factor for project success.
During the technical interview, you can also assess the company’s expertise with your desired tech stack. It’s crucial to ensure they have strong competence in your system’s core components like cloud platform, database engine, app orchestrator, etc. Don’t be discouraged if they lack experience with supplemental technology; the modern DevOps ecosystem is vast, and no team can master everything. If they have experience with a similar technology, they’re likely to adapt quickly. Unlike in-house engineers, who often work in silos and with the same stack for years, a DevOps as a Service team must constantly learn new technologies and tool integrations as they serve different customers.
As technology sectors expand, having specialized roles within the team is an added benefit. For example, bringing in a specialist for a specific task, such as an SRE, cloud architect, or Kubernetes administrator, is more efficient than relying on one person to handle everything. And this is also another reason why outsourcing is better than outstaffing: does your service company use engineering roles to provide you with a highly skilled team?
Organization of Processes
Once you’ve shortlisted potential candidates, it’s crucial to understand their workflow and project management routines. Key questions to ask include: How is communication with customers organized? How are tasks assigned and managed? How do they keep customers updated on task progress? Do they offer any guarantees on their work? These factors will give you insight into how smoothly your collaboration might run.
Estimating the Scope of Work
Accurately estimating the complexity of a DevOps project requires more than just a phone call. The process should be extensive, thorough, and meticulous. It’s essential to consider both business expectations and developers’ demands to gain a full understanding of existing and potential issues.
A detailed estimation not only provides clarity but also helps minimize unforeseen costs that might arise later. Imagine a scenario where the provider, upon completing their work, charges more because certain issues only became apparent after the project began. This could be a negative experience, especially if your budget is tight. A comprehensive estimation allows you to forecast ongoing expenses and agree on a fixed price for the project.
Standard Agreement Conditions
Carefully review the company’s standard contract, paying particular attention to the terms and conditions. Although these can be customized to your needs, the provider will likely adhere to the standard terms since their processes are tailored to them.
The contract should also include provisions for data safety and the security of your infrastructure, along with liabilities for non-compliance. This demonstrates the company’s diligence and commitment to their responsibilities.
Project Completion and Delivery
For DevOps as a Service, completion should not simply involve signing off on a certificate of acceptance. Providers that insist on this may pressure you to approve the quality of services before you can fully evaluate them. Given the nature of DevOps, the quality of services can only be truly assessed after the project has been live and in use for some time. Reputable companies understand this and include a probation period in their agreements, during which they remain available for technical support and consulting.
SRE and 24/7 Support
Ideally, a DevOps as a Service provider should not only build infrastructures but also offer round-the-clock support and maintenance. Why is this important?
Firstly, the availability of 24/7 support demonstrates the company’s commitment to high-quality service. It shows they are willing to go the extra mile, knowing that their support team will be responsible for handling any issues that arise. A provider that simply completes the work and moves on may be more likely to cut corners, leaving you with a solution that lacks consideration for long-term maintenance.
Secondly, if the company offers Site Reliability Engineering (SRE) services, it likely has multiple locations around the globe to cover different time zones. This global presence is excellent for creating efficient workflows, allowing for better scheduling of shared meetings, real-time communication, and quick issue resolution.
DevOps outsourcing with SHALB
With over 15 years on the market, SHALB has delivered over 300 successful projects across various sectors, including fintech, data science, blockchain, retail, and automotive. This extensive experience is reflected in the AWS partnership certification and positive recognition on the Clutch platform.
SHALB’s core expertise spans DevOps, Kubernetes implementation, and cloud-native technologies, including migration, microservices containerization, infrastructure as code, and multi-cloud environment building. With teams located across various time zones and specialized roles within the organization, SHALB is well-equipped to adapt to the diverse needs of its customers.
The company’s workflow is anchored in Agile principles, emphasizing a stage-by-stage approach. This includes a comprehensive review of a customer’s infrastructure, resulting in a detailed roadmap with suggested improvements and defined tasks. After project completion, we remain available for ongoing maintenance and technical support, with quality assured through the financial responsibilities outlined in the agreement.
When looking to future-proof your infrastructure against the challenges of tomorrow, consider the factors discussed in this article. A provider like SHALB, with proven expertise and a structured approach, could be a strong partner for your journey forward. Book a call or get in touch via online form to learn more.
The post From Trust to Expertise: How to Choose the Best DevOps as a Service Partner appeared first on SHALB.
]]>The post Securing Your Software Supply Chain: A Hands-On Guide to Consuming Open Source Safely. Part II appeared first on SHALB.
]]>
Vulnerabilities
A software vulnerability is a flaw or weakness in a system or program that could be exploited by an attacker to gain unauthorized control or compromise the security of the software or IT network.
The State of Software Supply Chain Security Risks research identifies vulnerabilities as the primary factor behind many software supply chain attacks. Moreover, vulnerabilities in open source code present a particular threat because of its public accessibility: adversaries are free to scrutinize it to identify and potentially exploit weaknesses. According to the 2024 ‘Open Source Security and Risk Analysis’ (OSSRA) report, 84 percent of the 1,000 codebases examined contained at least one open source vulnerability.
As shown in the figure below, the presence of existing security vulnerabilities is the main criteria when assessing the security of open source components:
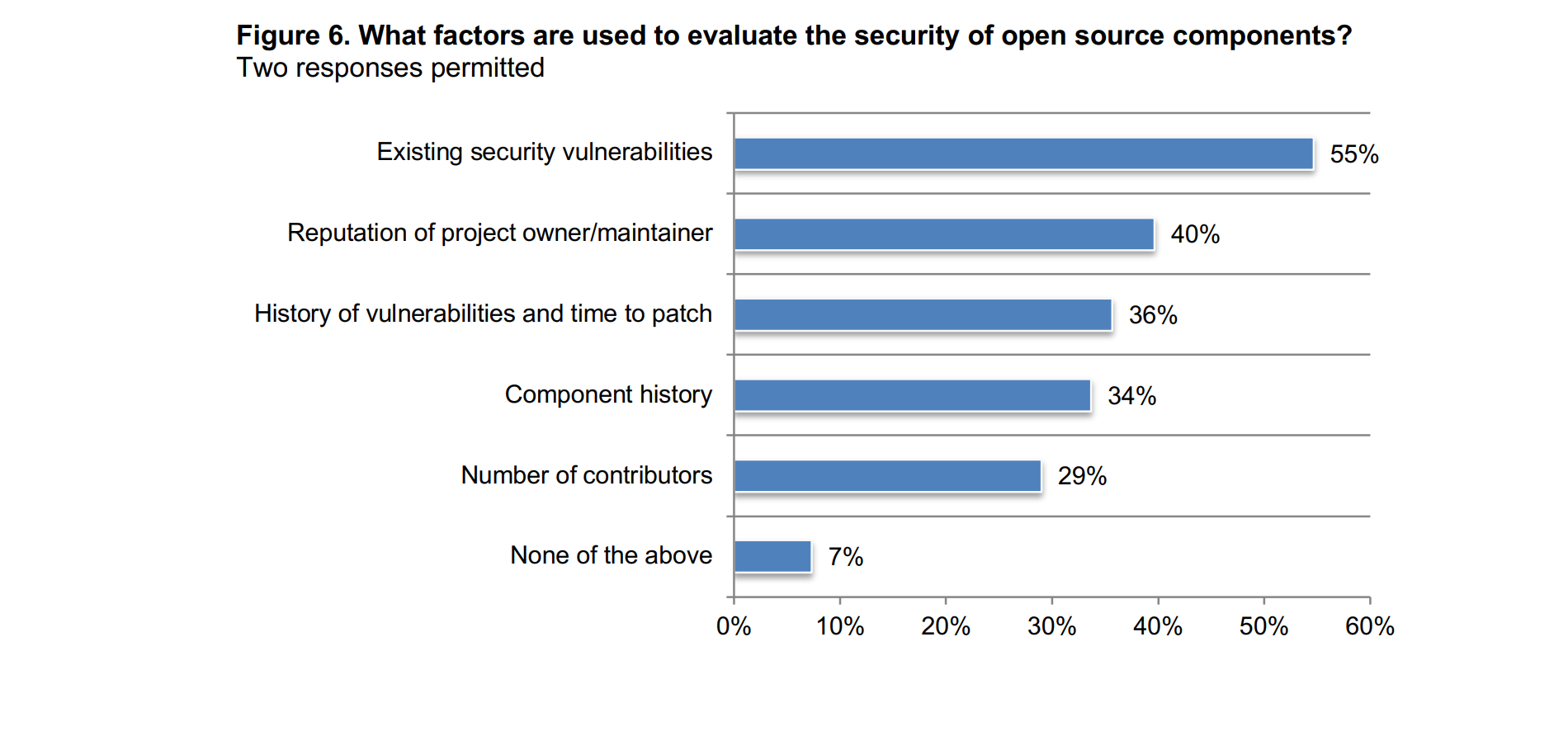
Source: Ponemon report: The State of Software Supply Chain Security Risks
There are many potential causes that could lead to a software vulnerability, ranging from specific coding errors to flawed architectural design. Moreover, given the complexity of modern applications, even following best practices during the coding and design stages cannot guarantee that an application is free of vulnerabilities. Regardless of how confident you are in the security of your software, it is crucial to implement measures to detect and address any vulnerabilities that may exist. Read on to know what actions can help prevent vulnerabilities from entering your supply chain.
Ways to handle software vulnerabilities
Vulnerability scanning
Vulnerability scanning involves identifying and evaluating potential weaknesses throughout all stages of the software development lifecycle, as well as threats related to the operating environment, such as cloud infrastructure. Conducted by software composition analysis (SCA) tools, it is a highly effective method for detecting most open source vulnerabilities. Key types of scans include:
- application scanning
- container scanning
- misconfiguration scanning
- compliance scanning.
Create and maintain SBOMs
An SBOM provides a detailed inventory of all open source components in your applications, including information on their licenses, versions, and patch status. A well-maintained, up-to-date SBOM is a powerful tool for securing your software supply chain, as it aids in assessing exposure and ensures that your code remains secure, compliant, and of high quality.
Stay informed
Being informationally proactive is an essential component of a secure software supply chain strategy. Make sure you have a reliable way to stay informed about newly discovered malicious packages, malware, and disclosed open source vulnerabilities. Seek out newsfeeds or regularly issued advisories that offer actionable insights and details on issues impacting the open source components listed in your SBOM. Public sources like the National Vulnerability Database (NVD) are a good starting point for information on publicly disclosed vulnerabilities in open source software.
Perform regular updates
Keeping your software up to date ensures you are running the most secure version with the necessary patches. In corporate software, vendors typically either update versions automatically or notify their customers when a new security patch is released. However, with open source software, it is up to the users to stay informed about the status of components and to download new versions as they become available.
Dependencies
Software dependencies are external libraries, modules and frameworks developed independently by individuals or groups and incorporated within a project. These dependencies are publicly accessible and available for anyone to use, modify, and distribute. While incorporating open source dependencies can significantly boost the development process, it also introduces potential security risks, particularly when these dependencies are not properly managed or monitored.
Despite this, many organizations neither know nor track their open source dependencies. Research on the State of Software Supply Chain Security Risks revealed that only 39% of respondents maintain an inventory of their open source dependencies, and of those, only a small portion (22%) use automated or policy-based mechanisms to approve or forbid the use of these dependencies.
How to manage software dependencies
Effective dependency management involves creating a detailed inventory of all components and continuously monitoring them for new vulnerabilities and compliance issues. If left unaddressed, vulnerabilities in open source libraries can expose the entire project to significant threats. Regularly updating and monitoring these dependencies is crucial for mitigating such risks.
Licensing
Software licenses outline the rights of developers, vendors, and end users, defining how those rights are protected. Open source alone has over a hundred licensing formats, each with its own specific terms and conditions. A key challenge in using open source code is ensuring that you stay within the boundaries of these licenses without violating their terms.
Failing to comply can lead to serious consequences, such as legal troubles, loss of intellectual property, lengthy remediation efforts, and delays in getting your product to market. That’s why it’s crucial to keep track of the licenses for your open source components and understand their associated obligations.
Common types of license-related issues include:
- License conflicts: When different software components within a single product have conflicting licenses, such as integrating open source code within proprietary software or when modified code fails to meet enterprise quality and security standards.
- Licensing snippets: The inclusion of code fragments taken from websites that lack clear terms of service, which are then incorporated into a project’s codebase.
- AI-generated code: Code produced by AI-powered tools, which raises questions about ownership, copyright, and licensing.
Best practices on open source licensing management
- Perform a detailed inventory of all third-party software components in your application, including both open source and commercial software.
- Review the licensing terms and conditions for each component to ensure they align with the intended use of your product.
- Verify that the licenses of different components are compatible with one another, as some may have conflicting terms.
- Implement automated scanning tools to identify and monitor license obligations and restrictions for each component.
- Seek guidance from legal experts to ensure compliance with all licensing requirements.
Lack of development
Before incorporating external code, evaluate how well the project is maintained. If you notice there’s been no activity within a year, it’s a red flag to pause and reconsider. A lack of development—especially in smaller projects—means no feature updates, no code improvements, and no fixes for discovered security issues, which significantly increases the risk of using that code.
Best practices for consuming open source safely
- Use automated tools to evaluate open source components, such as SCA scanners. These tools perform dependency and code printing checks, binary analysis, snippet analysis, and identify all dependencies included in the application and resolved during a build.
- Monitor your supply chain. Regularly inspect its components, as defined in your SBOM, to check for security issues, updates, and license conflicts.
- Follow the DevSecOps approach and integrate security into the design and development phases of the SDLC. This process includes threat modeling, secure coding practices, and regular code reviews to ensure that software is built with security in mind. Use dedicated frameworks, such as the BSA Framework for Secure Software or the NIST SDLC framework, to ensure safe coding.
- Practice code hygiene: Only incorporate code from trusted sources and well-maintained repositories.
- Conduct code reviews: Carefully examine the code of any downloaded software before integrating it into your project. Look for any known vulnerabilities, and consider using static code analysis to uncover potential security weaknesses that may not be immediately apparent.
Conclusion
Today, as organizations increasingly rely on the open source ecosystem to develop software, securing open source components is vital to the overall health of the software supply chain. The stakes are high, so safeguarding the software supply chain, primarily its open source elements, must be a cornerstone of any comprehensive cybersecurity strategy.
Best practices for securing a software supply chain include:
- Managing dependencies effectively
- Regularly updating software
- Ensuring the integrity of the supply chain
- Tracking the provenance of components
SHALB, a leading DevOps as a Service company, can help you safeguard and strengthen your software supply chain by implementing automated security mechanisms at every stage—from creation and build to deployment and runtime. Contact us today to learn more!
Resources:
The importance of supply chain security management
The State of Software Supply Chain Security Risks Report
2024 Open Source Security and Risk Analysis Report
What is software supply chain security?
A practical guide to software supply chain security
Secure at every step: What is software supply chain security and why does it matter?
What is Vulnerability Scanning?
The Complete Guide to Software Supply Chain Security
Why Should We Care About Software Supply Chain Security, and Why Now?
The post Securing Your Software Supply Chain: A Hands-On Guide to Consuming Open Source Safely. Part II appeared first on SHALB.
]]>The post Securing Your Software Supply Chain: How To Consume Open Source Safely. Part I appeared first on SHALB.
]]>
The consequences of compromising a single software supply chain can lead to cascading attacks across industries, impacting companies with revenue loss, legal issues, and damaged reputations. Using open source components amplifies these risks due to the complex web of dependencies involved, many of which remain untracked.
Industry research shows that over 96% of code in applications comes from open source, making supply chain security a critical concern. This article addresses the challenges of securing a software supply chain, with a particular focus on open source projects. In the first part, we define a software supply chain, explain its stages and explore ways to protect the components, activities, and practices involved at each stage.
Understanding the Software Supply Chain
Defining the software supply chain
A software supply chain is a network of components, actions, and practices involved in the creation and deployment of application code. In other words, it includes everything that directly or indirectly affects the code throughout its entire lifecycle. This includes details about the code’s components, the infrastructure it relies on, the inventory of cloud or on-premises services, and information about the origins of third-party components, such as GitHub repositories, codebases, or other open-source projects, along with their contributors.
Although each software supply chain is unique, most follow a similar foundational model. This model typically includes four phases —create, build, deploy, and run—and illustrates how sources and dependencies are transformed into artifacts that are then either integrated into other software or deployed as standalone applications. It is important to understand that any of these phases is potentially subject to attack. Therefore, securing the software supply chain involves safeguarding the components, activities, and practices at each stage of the process.
The figure below outlines the phases of the software supply chain, along with the security measures at each step.
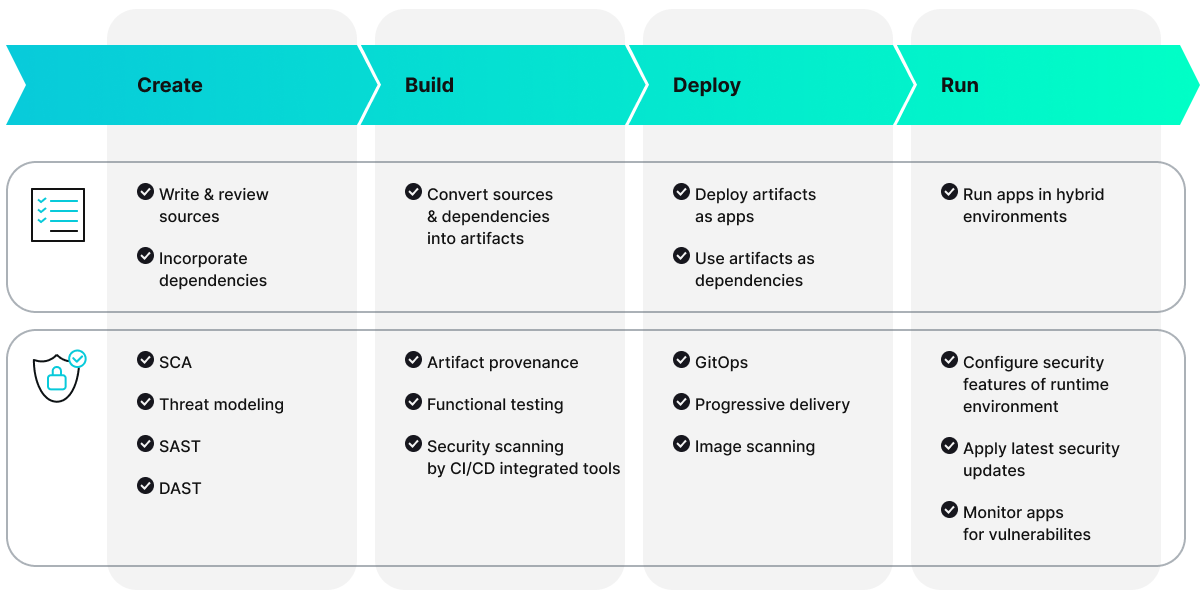
Key components and phases
Create
The “Create” phase involves writing and reviewing sources – an essential content stored in repositories and used for building software. Sources include code written by the internal team or third parties, container images created by operations, build tools, configurations, and infrastructure as code (IaC).
During this phase, software architects and developers also incorporate dependencies – external components like open-source libraries, third-party middleware, and standard development frameworks. Unlike sources, dependencies are not produced or reviewed in-house, making it twice as important to assess their reliability and verify their authenticity.
Finally, security scanning and testing tools are employed to identify vulnerabilities in both sources and dependencies. Techniques such as software composition analysis (SCA), threat modeling, and various forms of application security testing (SAST, IAST, DAST) are commonly used in this phase.
Build
In the “Build” phase, sources and dependencies are converted into artifacts through the use of build tools and platforms. Artifacts may include compiled binaries, container images, documentation, Software Bills of Materials (SBOMs), Vulnerability Exploitability eXchange (VEX) documents, and other attestations. Once created, these artifacts are stored in artifact repositories and published in package registries, making them accessible for the deploy and run phases.
The implementation of the build platform can differ between organizations but typically involves several key components: compilers and tools for transforming sources into artifacts, attestation tools for generating provenance, functional test suites, continuous integration and continuous deployment (CI/CD) pipelines, and security scanning tools, often integrated into the CI/CD process.
Deploy
In the “Deploy” phase, consumers access published artifacts to either incorporate them as dependencies in their software development projects or deploy them as workloads. IT operations teams often leverage GitOps to automate the deployment of version-controlled software, which helps accelerate feature delivery, enhance collaboration between development and operations teams, and improve consistency.
Deployment configurations are defined using Infrastructure as Code (IaC) and committed to source repositories. Consumers’ CI/CD pipelines then automatically download, test, and deploy updated versions of applications and infrastructure according to these configurations, ensuring a continuous and efficient deployment process.
Run
In the “Run” phase, consumers operate the resulting applications in hybrid cloud environments. Ensuring a secure runtime environment is crucial, and IT operations teams must configure the security settings of the underlying software infrastructure, including the operating system and container management platform, to meet security standards. They should also keep the runtime environment updated with the latest security patches for the operating system and platform. Additionally, IT operations teams must monitor applications for any reported vulnerabilities and active threats from both external and internal sources.
Now that we’ve outlined the basics of a software supply chain, we can move on to part II, where we’ll discuss supply chain security risks and best practices for safely consuming open source.
The post Securing Your Software Supply Chain: How To Consume Open Source Safely. Part I appeared first on SHALB.
]]>The post DevOps as a Service: Harnessing Efficiency in the Tech Landscape appeared first on SHALB.
]]>
What is DevOps?
DevOps is a cultural and technical approach that combines strategies, practices, and tools to accelerate application and service development. It emerged with the rise of cloud platforms and the shift away from on-premises hosting. By bridging the gap between development and operations, DevOps fosters strong collaboration among development, QA, and operations teams, often extending to include security (DevSecOps).
The main pillar of DevOps is automation that goes through all of its practices. By introducing automation across all stages of the software lifecycle, from development to deployment and maintenance, DevOps minimizes human effort, reduces the likelihood of errors in the application code, and speeds up the delivery process. This approach helps companies meet business requirements more efficiently and stay competitive in the market.
What is DevOps as a Service?
DevOps as a Service is an outsourcing model that allows you to reap all the benefits of comprehensive DevOps without hiring an in-house team. We’ve covered this topic in detail in previous posts. In short, this means having access to specialized DevOps skills and consulting without expanding your technical staff or bearing additional costs for workspace and employee taxes.
Compared to the traditional in-house approach, DevOps as a Service often results in better motivation among the hired team, as they aim to deliver excellent results to secure future contracts and favorable recommendations.
The great advantage of this model is also its full-service aspect: the provider manages all infrastructure and software-related processes, from Continuous Integration and Continuous Delivery to automated testing and infrastructure management. Let’s take a closer look at these elements.
Core Components of Devops as a Service
- Continuous Integration (CI): CI is a set of coding practices designed to ensure a consistent and automated process for building, packaging, and testing applications. CI involves continuously delivering code to a central repository each time it successfully passes build and automated tests. The important aspect of CI is delivering code in small batches, which makes it easier to catch and fix bugs early on.
- Continuous Delivery (CD): CD extends CI by automating the deployment of validated code to non-production environments like development and staging. At this stage, deployment to critical environments requires manual approval. However, this process can be fully automated as part of Continuous Deployment, also known as CD. In this setup, application changes pass through the CI/CD pipeline and are directly deployed to production environments after successfully passing all tests.
- Automated Testing: Testing is a crucial part of the software lifecycle, and automating it helps identify errors early in development, freeing up engineering resources. DevOps as a Service supports automated testing by providing the necessary infrastructure, including implementing continuous testing as part of the CI/CD pipeline, setting up environments for integration testing, and creating production-like conditions for performance testing.
- Infrastructure Management: DevOps as a Service enhances infrastructure and configuration management by using Infrastructure as Code (IaC), a practice that provisions and manages IT environments through code-defined resources. As a core DevOps practice, IaC automates the creation of environments, ensuring consistent configurations, replicability, scalability, and traceability of changes.
Integration with existing teams
DevOps as a Service integrates seamlessly into existing IT and development teams through close coordination and well-organized workflow. Highly result-oriented, DevOps as a Service teams prioritize customer needs and aim for efficient and transparent communication. By utilizing shared communication channels like task management systems and messaging platforms, they keep customers consistently informed about work progress.
Key benefits of DevOps as a Service
Access to Top Talent: Finding skilled professionals locally can be both challenging and costly. By outsourcing, you overcome geographical limitations and gain access to a global talent pool. This allows you to select candidates with the most favorable skill sets and rates, ensuring a cost-effective solution.
Rapid Project Initiation: Training in-house specialists can be a longtime process, delaying your projects. Outsourcing provides you with fully-trained professionals who have the necessary skills and knowledge to start working on your projects immediately.
Pay-for-Performance Model: One of the key benefits of outsourcing is that you only pay for the work outlined in your agreement and completed within the specified terms. This approach eliminates the need for expenses related to staff and workplace maintenance, inevitable with in-house DevOps model.
Broad Expertise: An outsourced DevOps provider’s team typically includes seasoned experts with experience in a variety of projects. The collective knowledge and skills of the team enhance the company’s expertise. If a particular engineer lacks the required skills, they can be replaced with a more qualified team member.
Challenges of DevOps as a Service
Integration with existing processes: For outsourced employees to deliver their best results, they should be seamlessly integrated into the team. This integration goes beyond technical skills, such as working with the technology stack chosen by the in-house team; it also includes interpersonal skills. The inability to fit into well-knit customer teams and develop efficient working relationships could be a serious blocker to successful adoption of DevOps as a Service.
Security and Compliance: For certain industries that handle sensitive customer information, such as fintech and healthcare, adhering to stringent security rules and industry standards is crucial. Their main priority is ensuring data security both in transit and at rest. To achieve this, DevOps as a Service teams must prioritize compliance by implementing encryption, access controls, and audit trails throughout their processes. Automated testing should also incorporate compliance checks to ensure that the software meets industry-specific regulations and standards, such as those in healthcare.
Conclusion
DevOps as a Service is the ideal solution for companies that want to achieve highest results without hiring in-house teams. With a dedicated team of professionals, a flexible development approach, and effective communication, this approach helps bring products to market more quickly and efficiently, providing a clear competitive advantage.
If you’re considering integrating DevOps as a Service, look no further than SHALB. Our team thrives on new challenges and stays ahead of the ever-evolving DevOps landscape to deliver the best solutions. Contact us today to elevate your DevOps journey!
The post DevOps as a Service: Harnessing Efficiency in the Tech Landscape appeared first on SHALB.
]]>The post The Cloud Era and Tech Innovations: What You Need to Know About IaC appeared first on SHALB.
]]>
In this article, we will explore what IaC is, focusing on its core principles, pros and cons, and future trends. We will also introduce popular IaC tools, explaining their basic functions and highlighting the differences between them.
Factors that set the scene for IaC
The mass adoption of cloud computing has significantly contributed to the rise of IaC that enabled efficient control over the growing number of cloud infrastructures’ components. Several factors have been vital in shaping the IaC concept:
- Shift to cloud-native development: The widespread use of containers has led to the rise of immutable infrastructure, an approach to provisioning that replaces virtual resources instead of modifying them. IaC has enabled the codification of infrastructure resources as templates, allowing for quick and easy setup of new environments.
- Need for automation in modern stacks: Modern infrastructures can consist of hundreds of components, making manual provisioning a daunting and impractical task. IaC introduced automation that allows organizations to manage their infrastructure at scale, avoid configuration drift, and swiftly apply changes across multiple environments.
- Increased role of developers in operations processes: In the cloud-native world, developers are increasingly required to handle provisioning tasks. IaC simplifies these operations, allowing developers to spin up ready-to-go infrastructures by merely executing scripts. Additionally, the accountability and transparency provided by IaC foster better collaboration between development and operations teams.
- Need for swift infrastructure changes: The dynamic nature of cloud environments demands infrastructures that can be rapidly spun up, scaled, and taken down as needed. IaC facilitates this flexibility, with all modifications being implemented through updates to configuration files.
Understanding Infrastructure as Code
Definition and principles
Infrastructure as Code (IaC) is a practice that involves managing and provisioning computing infrastructure through machine-readable configuration files instead of manual configuration. By introducing automation throughout all infrastructure processes, IaC reduces manual tasks while ensuring the consistency, repeatability and scalability of infrastructure setups.
The fundamental idea behind IaC is straightforward: treat your infrastructure as you would software and data. This means applying the same practices used in software development to your infrastructure, including version control, testing infrastructure code, and implementing continuous integration and deployment.
How IaC works
IaC is implemented through specific tools that automate system provisioning using their internal algorithms. Depending on the approach, IaC can be executed either declaratively or imperatively. Let’s take a closer look at these two methods.
Imperative approach
The imperative, or procedural approach is a “how” method: it focuses on outlining the precise steps needed to achieve the desired outcome. Therefore, it implies providing detailed instructions or scripts that specify the exact order in which to execute tasks. This approach allows for granular control over configuration and deployment by detailing each step; however, it requires advanced coding skills from engineers.
Declarative approach
In contrast, the declarative approach emphasizes the “what” rather than the “how.” Using a domain-specific language, engineers specify the desired end state in configuration files, leaving it to machines to decide what needs to be done and in which way to achieve this. The declarative code is easier to manage and requires fewer coding skills.
IaC tools
There is a wide range of tools available for implementing IaC, each designed for different use cases and offering various approaches, configuration methods, scripting languages, and file formats.
Early IaC tools were more procedural, focusing on the specific steps required to reach the desired state, such as Chef and Ansible. Their code contained elaborate instructions, and so was difficult to read and understand.
With cloud-native development the trend moved towards a more declarative style of IaC, with tools like Terraform and AWS CloudFormation leading the way. Their code is lighter and more readable as it consists primarily of configuration settings.
The big advantage of declarative tools is their ability to store state: by constantly comparing the actual state with the desired one, they “know” when something fails and act to reconcile the state. The continuous drift check performed by declarative tools allows them to identify what needs to be changed, added, or created.
The table below highlights popular IaC tools and summarizes their most distinctive features.
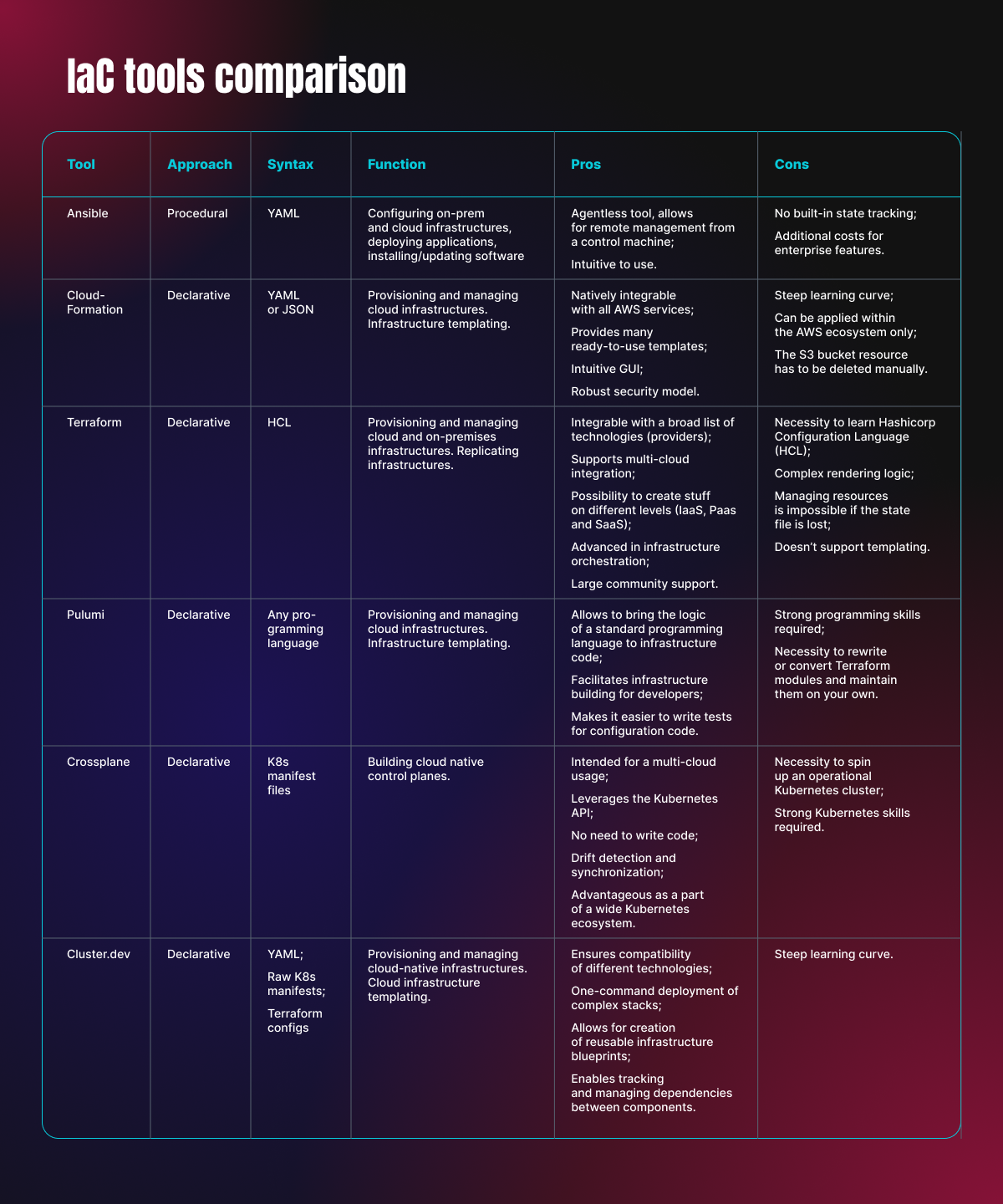
Benefits of Infrastructure as Code
Implementation of the IaC practice allowed to efficiently address the following challenges:
- Consistency and repeatability. One of the main issues with manual infrastructure setup is its unpredictability: the same script may yield different outcomes every time it is executed. In contrast, codifying infrastructure provides a template that ensures you can deploy the same set of resources repeatedly, achieving consistent results across different cloud platforms.
- Speed and efficiency. IaC takes a huge load off engineers by automating the tasks of configuring, deploying, or redeploying infrastructure after every change. With IaC, you can quickly apply a single configuration across multiple environments. When updates are needed, you simply adjust the configuration files, and the IaC tools handle the deployment and provisioning automatically.
- Keeping up with changes and updates. Manual infrastructure setup can make tracking changes a guessing game for the rest of the team: it’s hard to know who made what changes and why. By keeping infrastructure code in a version control system (VCS), IaC provides clear visibility of changes, fostering better collaboration between teams.
- Fewer Mistakes. IaC helps ensure higher quality code through VCS-enabled code reviews. Since changes to infrastructure are made via code that undergoes checks, the risk of crashing the infrastructure by making direct changes is significantly lower.
- Documentation. IaC code is clean and readable by both machines and humans. Additionally, it’s self-documenting, providing a clear overview of existing resources and configurations.
- Cost Optimization: IaC provides a complete inventory of your cloud resources, detailing which services run on which platforms. Regular code reviews enable you to identify idle resources and shut them down, helping to optimize costs.
Challenges
Adherence to routine. When implementing IaC, it’s crucial to strictly adhere to the rules and practices agreed upon with your team. Although it may be tempting to make quick minor changes manually instead of following all the procedural steps of the IaC pipeline, doing so undermines the core principle of IaC. At first avoiding manual changes might seem like a longer road, but ultimately it saves time in the long run.
Time investment in learning. Adopting any new technology, no matter how user-friendly, demands a significant investment of time and effort for successful onboarding. When working with IaC tools, you need to understand their unique logic and domain-specific languages, which can vary from tool to tool. Achieving proficiency with these tools requires a certain level of commitment and time investment in the beginning.
Spread of mistakes. If unnoticed, an error in the codebase can be automatically propagated across multiple environments, leading to widespread misconfiguration and other issues.
Future trends
Victor Farcic, a Developer Advocate at Upbound, believes that the future of IaC tools is closely related to Kubernetes. This technology has become so deeply ingrained in modern IT environments that it will eventually operate behind the scenes, much like hypervisors: everyone who creates a virtual machine in the cloud uses them, often without even knowing they exist. According to Farcic, the current IaC toolkit will evolve into a new generation of tools called control planes. These tools will feature drift detection and automatic synchronization, allowing machines to detect changes in the current state and remediate them without waiting for human command. Additionally, these tools will leverage the Kubernetes API and a broad ecosystem of integrable tools.
Among the tools that extend Kubernetes will also be cloud controllers for Kubernetes: provider-specific tools designed to define and use cloud resources directly from Kubernetes. One such example is AWS Controllers for Kubernetes (ACK). These tools operate by making the Kubernetes API extensible to include resources outside of Kubernetes. With cloud controllers, you can describe the required resources in a Kubernetes manifest, enabling the Kubernetes API to create them, rather than creating them via the cloud console.

IaC tools evolution diagram
The growing trend to multi-cloud strategy will drive the rise of cross-cloud functionality that enables seamless integration of stacks running on different platforms. IaC tools with cross-cloud capabilities will be in the highest demand as organizations seek the most efficient ways to manage infrastructure across diverse platforms.
Conclusion
Infrastructure defined as code offers many advantages over manual provisioning, including version control, testing, faster provisioning, and software delivery. In the era of cloud-native computing, it’s no overstatement to say that IaC has become a cornerstone of modern IT strategy. As a key DevOps practice, it introduces automation at the infrastructure level. Its integration with established technologies like Kubernetes is paving the way for the emergence of more autonomous systems capable of self-optimization.
If you consider the future of your cloud infrastructure management, start your journey with SHALB and explore our comprehensive IaC services. Discover how SHALB can streamline your infrastructure setup and management, ensuring a seamless and optimized cloud experience.
The post The Cloud Era and Tech Innovations: What You Need to Know About IaC appeared first on SHALB.
]]>The post Boosting Observability in 2024: Current Challenges and Trends appeared first on SHALB.
]]>
Observability is based on three pillars: monitoring, logging, and tracing. The traditional approach involves using metrics to gain insight into systems or applications and consolidating the analysis of logs and metrics. While these practices still remain effective, the era of distributed environments requires reconsidering this approach to bring better results. In this article, we will explore the challenges organizations face when trying to implement observability in their environments, and the current trends aimed at mitigating them.
Observability Challenges
Complexity of Systems: Modern multi-cloud environments are becoming increasingly distributed. According to a study from 451 Research, 98% of enterprises use or plan to use at least two cloud providers, and 31% are using four or more. With services scattered across different platforms, organizations struggle to monitor operations and process the vast volumes of data they generate.
Overwhelming Data Volumes: As organizations track more services, they rely on numerous data sources for insights into their applications, infrastructure, and user experience. A survey by Dynatrace found that a typical enterprise uses an average of 10 different observability or monitoring tools, each generating vast amounts of data in different formats. Managing this deluge of data exceeds human capabilities.
Fragmented Vision: Many observability and monitoring tools operate in silos, making it difficult to construct a comprehensive view of a system’s state. Tool proliferation leads to challenges in processing disparate data from different sources, resulting in the absence of both a single source of truth and unified approach to data management.
High Data Storage Costs: Multiple tools and services generate vast amounts of data that must be stored and analyzed to provide an historical perspective on system performance, security, and health. Compliance requirements often necessitate long-term data retention, further driving up storage costs.
Lack of Experienced Staff: The Observability Pulse Report 2024 highlights that organizations are hindered by a lack of expertise on their way to achieve observability, with nearly 48% of respondents citing this as their primary challenge.
Vendor Lock-In: Organizations are concerned about their data being tied to specific vendors, viewing it as a potential liability. Specifically, they worry about the security and safety of their data under such conditions.
The reports conducted by observability market leaders indicate that organizations become increasingly aware of the importance of observability for their applications and infrastructure. However, in their pursuit to gain it, organizations grapple with scaling tools and processes, managing large volumes of data and the associated costs. Current observability trends are shaped by these challenges and aim to mitigate them.
Observability Trends
Coalescence of observability, security and IT tools
The explosion of signals produced by modern multicloud environments generates volumes of data that cannot be effectively handled by disparate tools. To manage this, organizations turn to intelligent observability platforms – holistic solutions that combine observability, security, and IT tools. Equipped with advanced automation, AI and analytics, these platforms facilitate efficient workflows by enabling automation of smaller tasks.
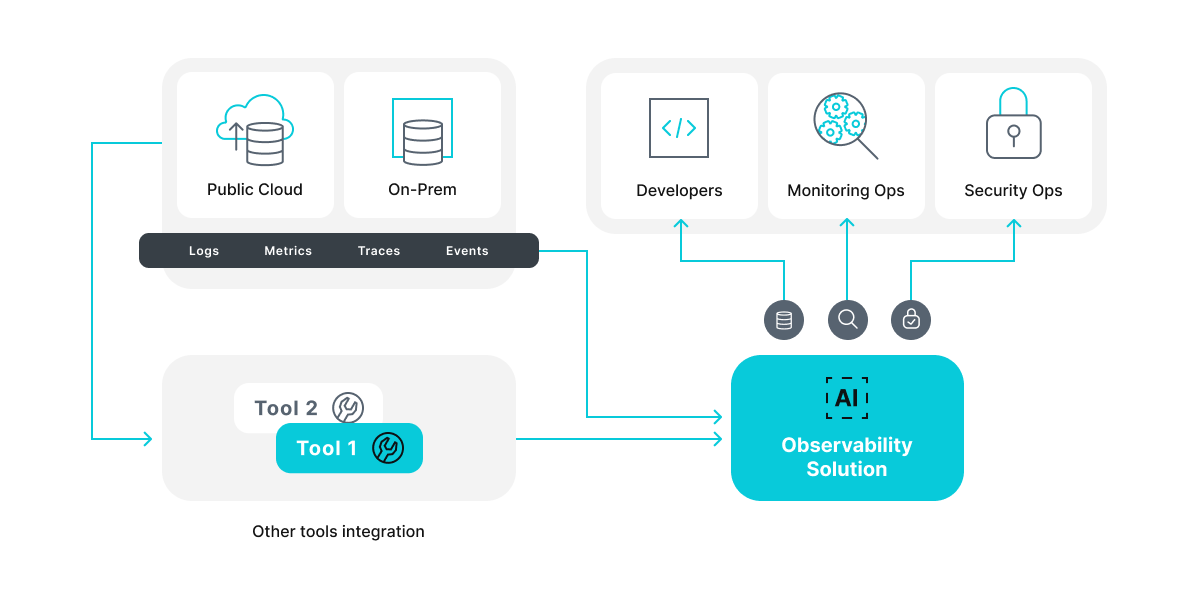
Operational principle of unified observability platform
This unified approach is also crucial for security, as it provides SecOps teams with broader context to understand their environments and distinguish important signals from noise. With real-time insights into system and application behaviors, security teams can be more proactive in identifying and addressing potential security issues before they escalate into major problems.
Advantages of using unified platforms include:
- Simplified data collection
- Single source of truth for data of different kinds
- Holistic view of your enterprise systems
- Automation of smaller tasks
- AI-based analytics
- Enhanced security measures
FinOps and reduction of cloud costs
According to the Observability Pulse survey, costs are a major challenge prompting organizations to reassess their observability strategies. To reduce cloud storage expenses, organizations are more selective about the monitoring data they collect. This demand for financial transparency has led observability platform providers to integrate advanced financial tools, allowing expenses to be correlated with profit centers.
AI’s role is important but secondary
Despite the excitement surrounding AI’s potential, its role in observability remains supplementary. Experts agree that while AI can reliably detect anomalies and alert staff, a human still needs to be at the center of the scheme connecting various elements of a complex system. The 2024 Observability Survey from Grafana Labs highlights a critical reevaluation of AI’s role, emphasizing the need to balance human expertise with AI-driven automation.
The downside of the widespread adoption of AIOps is that the observability market is flooded with similar products, with only a few companies standing out. Technology leaders predict that the maturity of AI, analytics, and automation capabilities will be crucial in selecting vendors and partners. Moreover, given the acute shortage of expert staff, advanced automation options will be a key differentiator for vendors. Organizations will seek solutions that automate time-consuming, low-skilled tasks or otherwise enhance the productivity of their existing teams.
The slide below displays the AI/ML features that organizations cite as the most sought-after in their observability practices:
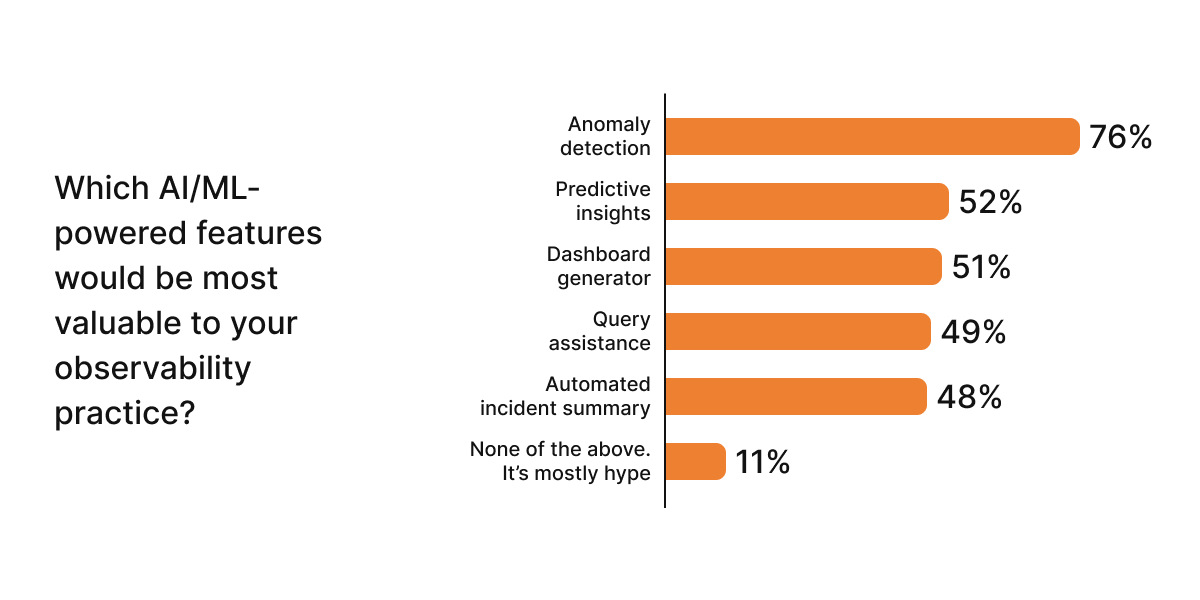
Source: Grafana Labs’ 2024 Observability Survey
Boost of open standards
The impact of open source is growing as organizations seek to avoid vendor lock-in. According to Grafana Labs’ report, OpenTelemetry is emerging as a leader in application observability, while Prometheus remains the de facto standard in infrastructure observability.
According to Arijit Mukherji, a distinguished architect at Splunk and one of the contributors to their Observability Predictions 2024, open standards can revolutionize automation processes leading to bigger things and better results. Mukherji believes that as automation takes over smaller parts of human workflows, open standards help them interoperate with each other leading to bigger results.
Main Takeaways
- Organizations are increasingly adopting centralized observability solutions as they track more services.
- Costs remain a primary concern, driving organizations to adapt their observability strategies to reduce expenses.
- AI is gaining momentum as a powerful yet supportive technology in observability.
- The integration of security and observability tools provides a broader context, enabling proactive response to potential issues.
- Open standards are flourishing as organizations seek to avoid vendor lock-in.
The post Boosting Observability in 2024: Current Challenges and Trends appeared first on SHALB.
]]>The post Pitfalls of Cassandra cluster upgrade in Kubernetes appeared first on SHALB.
]]>
Backstory
A client approached us with the task of upgrading their Kubernetes cluster, which hosted their cloud software. This was a private GKE cluster, and Google was about to stop supporting its specific version. Failing to upgrade could result in system failure, leading to downtime and potential data loss—a devastating blow to the client’s reputation.
The customer’s business focuses on organizing and managing parking lots in major cities. They develop and rent out a SaaS platform that enables easy startup and management of city parking businesses worldwide.
Considering the international scope of their business and plans for future growth, the customer chose Cassandra as the primary database for their application. As a distributed database, Cassandra supports synchronization across multiple nodes located in different regions. This means that lag between nodes doesn’t impact its performance. To enhance Cassandra’s scalability and availability, it was deployed within a Kubernetes cluster.
Unprofessional approach to infrastructure building
The biggest problem with the customer’s existing solution was its inconsistency and non-compliance with best infrastructure-building practices. Without an in-house DevOps team, the client hired various freelancers to configure their infrastructure components. Consequently, their systems were fragmented and difficult to manage. In hopes of improving their setup, they reached out to SHALB for assistance.
The first issue we encountered was that all applications, both stateless and stateful, were running in a single namespace. This bad practice complicates cluster management and impacted our work from the start. When we tried to clone the Kubernetes cluster for testing, the process failed due to an error in one of the applications. If the applications had been running in separate namespaces, we could have easily resolved this by disabling the problematic namespace and manually configuring the troublesome application after the cluster was initialized. Furthermore, this architectural decision compromised cluster restoration since Google retrieves clusters from backup by namespaces.
Despite positioning itself as an international business, the company’s infrastructure was only partially codified. Whenever they wanted to launch a new environment they had to reproduce stack configurations manually, which required a lot of effort. Additionally, their Kubernetes cluster lacked autoscaling and was constantly operating at full capacity. According to our estimations, implementing even basic autoscaling could have reduced their cloud costs by up to 60 percent.
We prepared and presented the client with a comprehensive infrastructure improvement plan, the first step of which was to describe the infrastructure with Terraform code. Codifying the infrastructure is essential for process automation, as it ensures minimal recovery time after failovers, simplifies scaling to multiple regions, and optimizes cloud costs by providing transparency of the services running in the cloud. The roadmap also emphasized the importance of running applications in separate cluster namespaces and implementing autoscaling.
Kubernetes cluster upgrade
Upgrading the Kubernetes cluster required upgrading all the applications running within it, including ElasticSearch, Cert Manager, and Cassandra. These applications were deployed using Helm files and custom bash scripts embedded within a dedicated image sourced from a public GitLab repository. The problem arose with the Cassandra application Helmfile: it was no longer supported since Cassandra developers switched over to an operator to deploy the application. Consequently, the deprecated Helmfile couldn’t deploy the K8ssandra Operator to a Kubernetes cluster of a newer version. Furthermore, our attempts to upgrade the image from the public repository resulted in the disappearance of the bash scripts that managed application deployment.
Finally, we had to resort to manual upgrades for each application instead of conducting comprehensive upgrades through code changes.
Upgrade of Cassandra clusters
The customer used the K8ssandra Operator to deploy Cassandra to Kubernetes. On one hand, operators streamline application installation and management on Kubernetes. On the other hand, they also introduce another configuration layer that can potentially lead to errors. And this was the case in our situation.
The issues already started emerging during the initialization of a new Cassandra cluster. As it turned out, these problems stemmed from the specifics of the private GKE cluster—a highly secure Kubernetes implementation hosted on Google’s infrastructure. The enhanced security measures of the private GKE cluster implied configuring firewalls even between applications running within the same cluster, and that was the issue.
Finally, we managed to install the cluster using the K8ssandra Operator by opening the port for the application and adding it to the cluster firewall rules—an unconventional solution proposed by an Indian developer. Interestingly, we received no feedback from Cassandra developers throughout this process.
Data synchronization between clusters
One of the default features of Cassandra is its support for cluster synchronization: when a new cluster is connected, Cassandra treats it as a new datacenter that requires synchronization. After synchronization is complete, you can switch off the old cluster and designate the new one as the main. We successfully tested this approach in the staging environment. However, when we tried to replicate it in production, we encountered a failure with an error that we couldn’t find any information about, even after extensive searching on Google.
After browsing various forums, we stumbled upon a potential solution suggesting the deletion of the CustomResourceDefinition (CRD). Upon reinstalling the cluster, the operator would generate a new CRD, which supposedly had to resolve the issue.
Unfortunately, this proved unsuccessful. To make things worse, deleting the CRD led to the failure of the production cluster and the loss of the primary database, on which other clusters relied for synchronization.
Dysfunctional backups
The situation was certainly frustrating but we were prepared for it. Surely enough we had copied all the data before deleting the CRD, so we had at hand a Cassandra backup from Medusa, a dedicated tool for Cassandra backup and restore. Initially, we were optimistic about using this backup. However, to our dismay, restoration from the backup failed due to some dysfunction in Medusa. Despite Medusa reporting successful restoration, each attempt resulted in an empty database. The thing that ultimately saved us were the Persistent Volumes: fortunately, they remained in Google Cloud after the failure of the old cluster, preserving all of its data.
In the end, we opted to create a new cluster, reducing its size to just one node, and connected this node to one of the remaining volumes. Thankfully, it worked – the data was successfully restored, and just in time: it was already morning, and cars were starting to appear in the customer’s parking lots.
Conclusion
Finally, considering all the issues outlined above, we opted for a more conventional and time-proven approach: deploying the Cassandra database outside of Kubernetes. In both staging and production environments, we provisioned virtual machines, installed Cassandra without using the operator, and successfully migrated all the data. This strategy proved effective, with Cassandra functioning smoothly and without any issues. For backups, we implemented a snapshot-based solution, which not only meets the customer’s requirements but also simplifies maintenance and enhances reliability.
Key lessons learned from this experience include:
- Working with an infrastructure set up by others can be exceptionally challenging but feasible.
- Unknown infrastructures may harbor hidden issues that can significantly prolong seemingly simple tasks, such as upgrading Kubernetes versions. It’s crucial for both you and your client to acknowledge this before starting a project.
You may ask why we would tell you all this. We shared these insights to underscore SHALB’s commitment to excellence and the proficiency of our team. Contact us to witness it firsthand! We build next-gen infrastructures according to best practices, and, which is no less important, never let our customers down.
The post Pitfalls of Cassandra cluster upgrade in Kubernetes appeared first on SHALB.
]]>