一.背景
业务需求使然,API接口负责收集用户传递上来的json数据,为了保证接口性能和数据的可靠性。我们没有直接拿到数据,然后存储到mysql或者kafka,而是直接使用最稳妥的方式,写文件。之后采用filebeat对数据文件进行采集,最后推送到Elasticsearch进行存储便于检索。
为什么选择filebeat采集文件的这种方案,而不是自己实现或者采用别的方案呢?
1.filebeat资源占用小、跨平台、稳定
2.filebeat推送数据到Elasticsearch等都有对应的重试机制,就算是挂了也能尽量保证数据采集的offset的正确性,防止数据漏采集或者多采集的情况
但同时也会带来一个问题就是,如果防止filebeat某种情况下降数据重复推送到Elasticsearch导致出现多条重复数据呢?
二.分析与解决
2.1 指定@metadata._id保证唯一性
查阅官方文档,我们可以在这一章看到有3种方式来实现指定插入到Elasticsearch可以指定_id的值可以用我们的业务字段进行设置,同时自己自定义设置。例如我们有一个业务call_id是能保证唯一的,那么我们指定这个call_id字段作为_id即可解决由于filebeat重试导致推送多条重复数据的情况。在已经设置@metadata._id的情况下并且没做其他操作,那么filebeat调用Elasticsearch的_bulk API接口,使用action: create进行插入数据. (create的基本原理是, 根据_id判断数据,如果数据已经存在则忽略插入操作,如果不存在才插入)
文档详情地址: 文档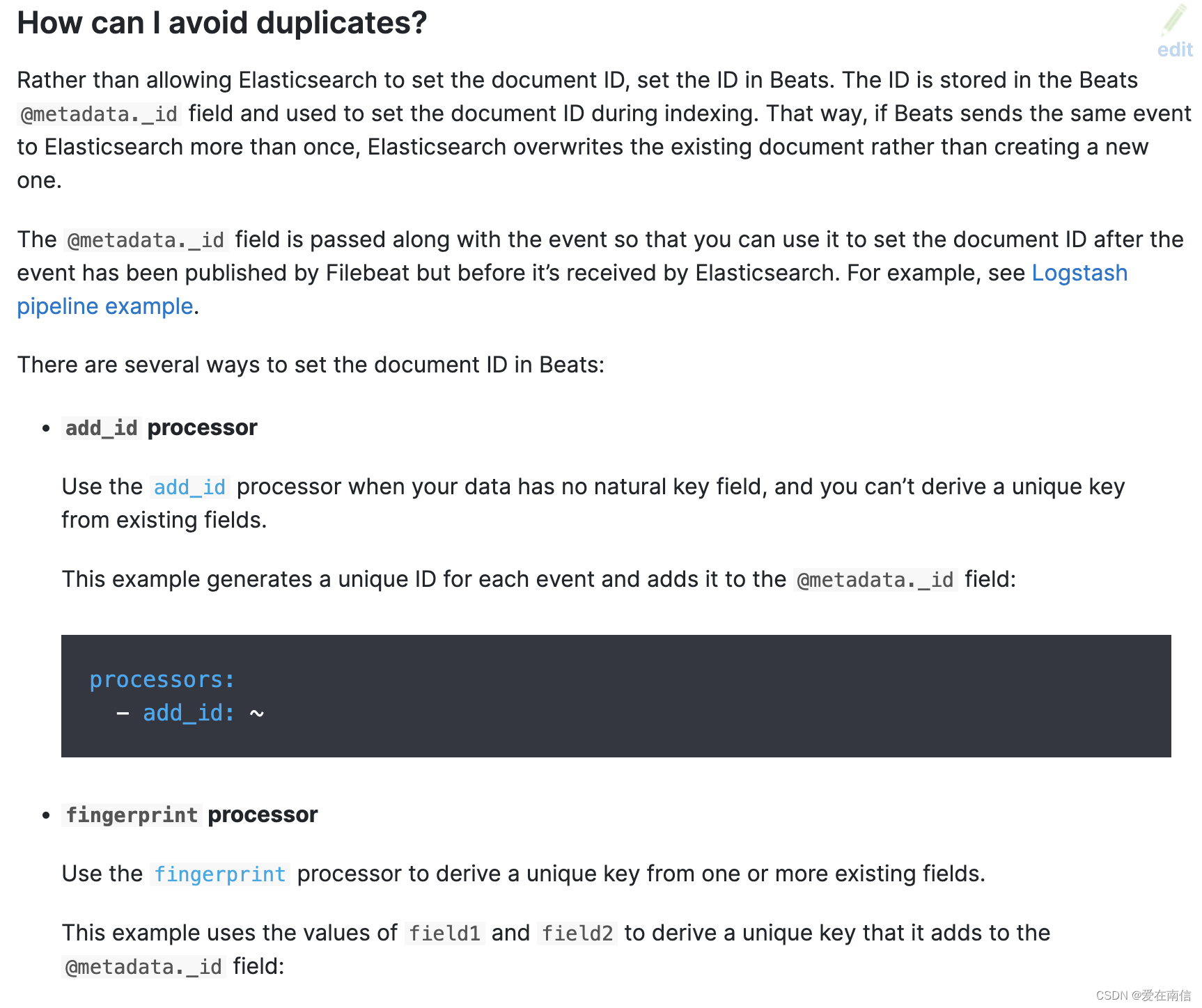
2.2 指定@metadata._id,但是希望action是index而不是create
相对上面的情况,我们有时候希望的是,相同_id存在的情况下是后面推送的数据是覆盖而不是丢弃。这个时候怎么办呢? 找遍全网资料和文档资料,都没找到能解决的办法。
后来直接看源码分析吧。既然是调用了Elasticsearch的_bulk API, action字段是index还是create到底filebeat源码是怎么处理的? 是直接写死了create, 还是说这个action可以通过配置的方式进行设置呢? 带着疑问开始找源码。 果然找到了:
调用_bulk API的地方: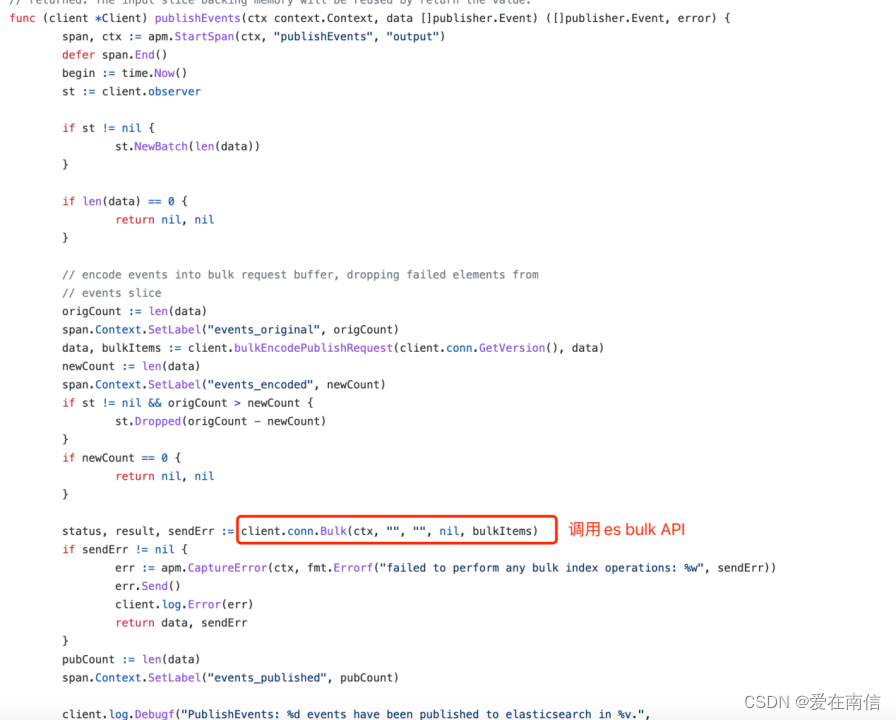
再继续往下看,怎么拼的post请求参数:
关注opType变量是什么东西?难道是index、create这些么?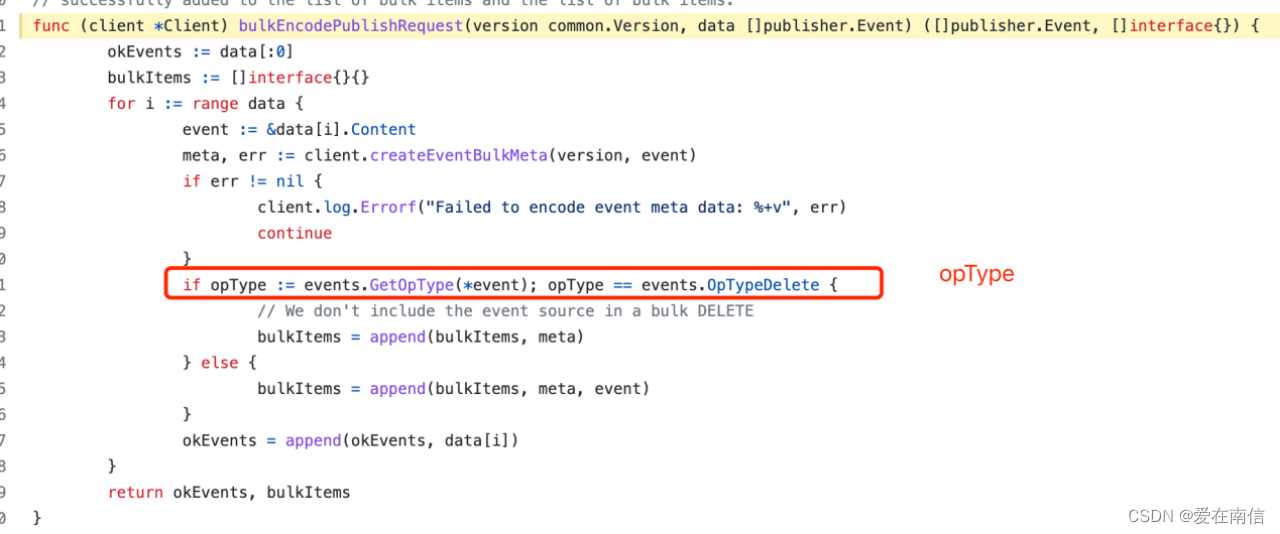
搜索OpTypeDelete关键词: 代码地址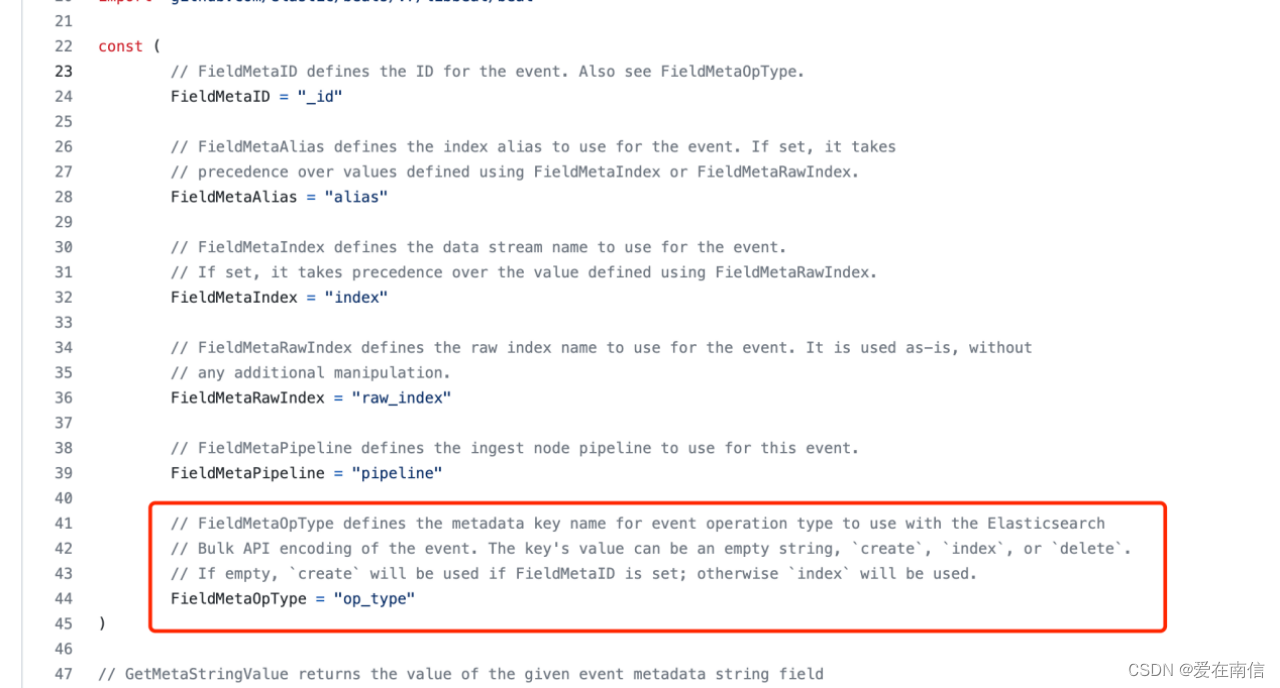
翻译一下:
//FieldMetaOpType定义用于Elasticsearch的事件操作类型的元数据键名称
//事件的批量API编码。键的值可以是空字符串、“创建”、“索引”或“删除”。
//如果为空,则如果设置了FieldMetaID,将使用“create”;否则将使用“索引”。
由此我们看出来,opType是可变的,那我们可以在配置文件还是数据上改变opType呢?
上面清楚的说明了,如果我们的@metadata._id设置了,则使用create. 否则使用index.
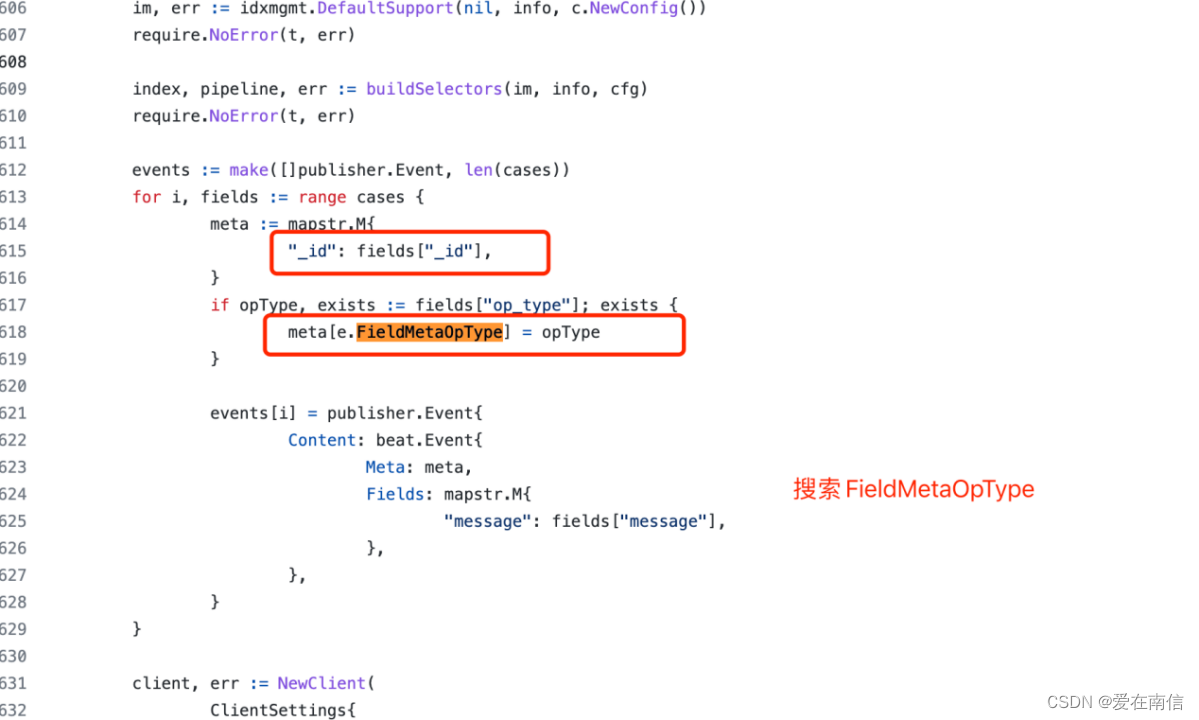
搜索FieldMetaOpType, 看到, 原来如此, event的@metadata对象是一个map,可以通过key获取value.
那么我们只要在@metadata对象设置@metadata.op_type=”index”即可
如何设置@medata.op_type=”index”呢? 只要在processors加一个script处理即可:
1 | processors: |
这个实例也告诉了我们两件事, 那就是:
1.就算是官方文档也不可能事无巨细的写在上面, 如果官方文档没有的,可以尝试从源码入手,也是一个不错的选择。
2.这种开源级别的项目作者是真牛批,已经把这些情况都想得很周到,没有写死在代码中。这就是大牛写的代码样例,我们平时也可以多借鉴一下这种思想。