一.背景
大清早的收到一台服务器的内存占用高达98%的钉钉告警。 回想了一下,这台服务器没跑什么业务啊,咋从凌晨1点就开始告警呢? 赶紧登录服务器,top 按照内存倒序一下,没发现占用特别大的进程。内存监控图如下: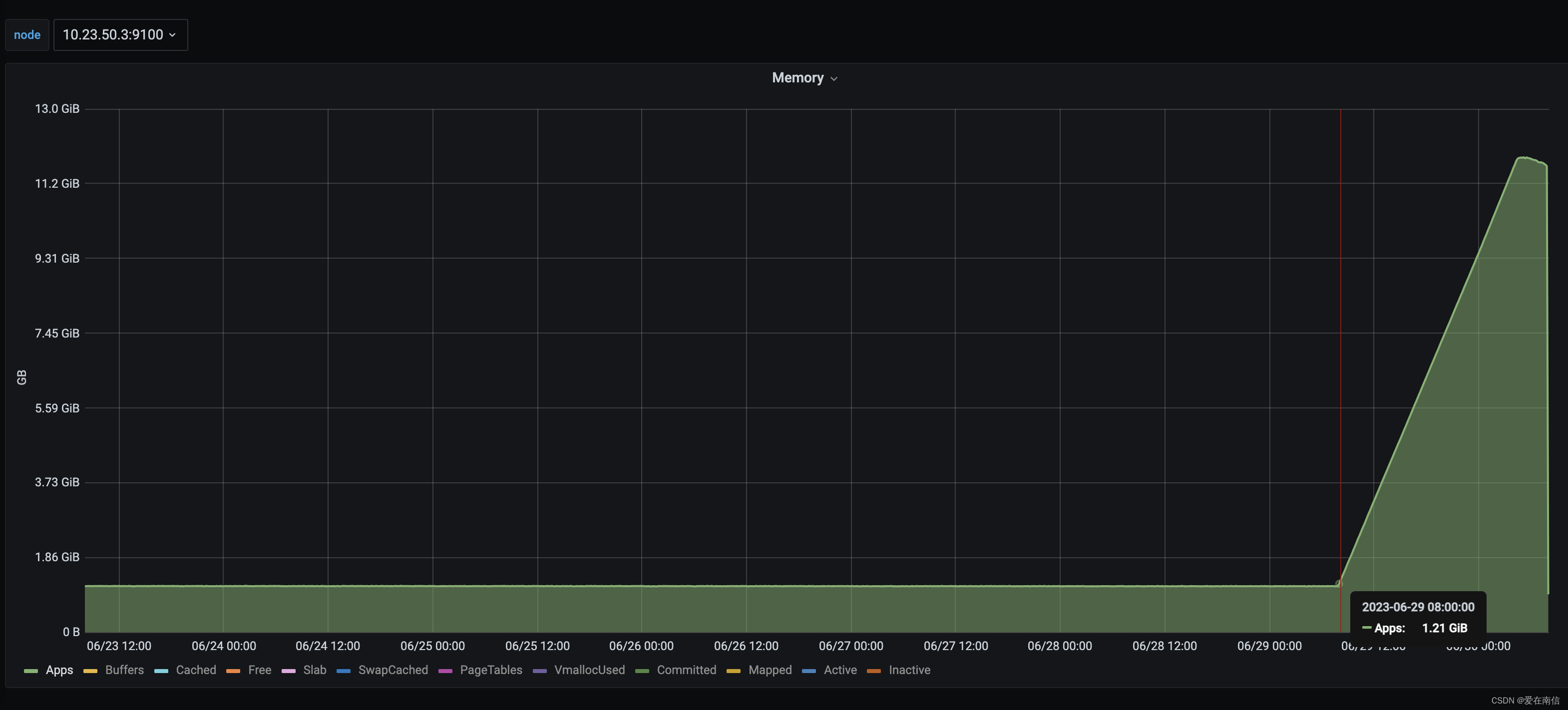
但是发现了很多sendmail和postdrop进程,统计了一下这两个进程高达4-5K个进程。难怪负载和内存占用很高, 当时来不及分析原因,先解决问题再说。
sendmail和postdrop进程 应该是和业务和系统运行无关的,先全部kill再说:
1 | killall sendmail && killall postdrop |
OK执行完毕后,内存和负载下来了。
此时有时间分析原因了,网上找了一些资料,有些朋友也遇到过这个问题,大多数是和crontab定时任务有关系。 我纳闷了?这个玩意和crontab又有什么关系呢?
原来crontab有一个配置和机制, 默认配置如下: MAILTO=root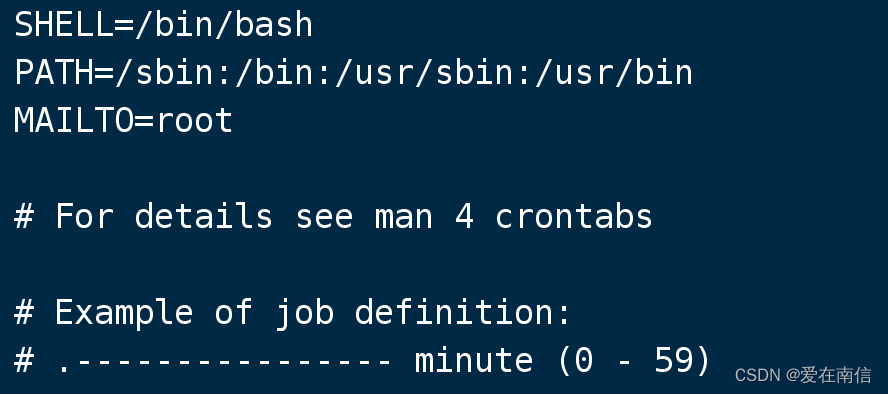
机制就是,当MAILTO=root这个配置存在:
1 | 1.如果定时任务没有将错误输出和标准输出写到文件, 则在crontab发生错误时,触发发送邮件操作 |
二.验证与实验
1.MAILTO=root不修改,定时任务没有重定向
crontab配置如下:
1 | SHELL=/bin/bash |
明显并没有/usr/bin/my这个可运行程序,此时查看/var/mail/root
有新内容产生,说明如果配置了MAILTO=root, 且定时任务没有将标准错误和标准输出到出,则定时任务报错时发送邮件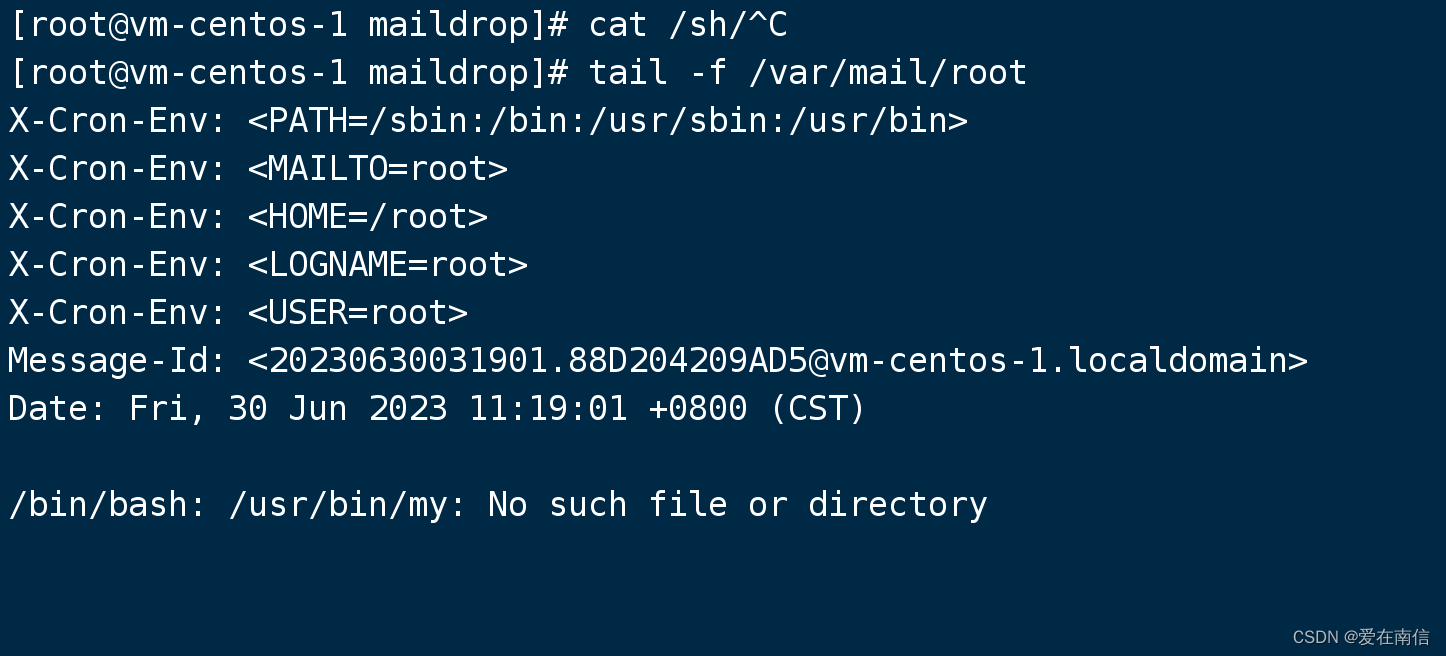
我将定时任务改为:
1 | * * * * * root /bin/bash /usr/bin/my &>> /sh/my.log |
此时查看邮件没有内容更新了,大家可以实操验证一下。
2.MAILTO=”” 关闭整个邮件通知机制
那如果定时任务有很多,想关闭这个mail通知机制怎么办呢? 每个任务都添加 &>> xx.log 显然不够优雅, 写起来也麻烦,要是有几百个定时任务都这么修改要疯。
直接将MAILTO=root改为MAILTO=””, systemctl restart crond重启定时任务即可。 这样就不会在定时任务发生错误时,发送邮件了。
三.故障根本原因分析与处理
1.磁盘inode没监控,导致占满100%,sendmail和maildrop报错,堆积僵尸进程
其实配置MAILTO=root本身没什么问题,本次故障根本问题还是inode使用率没做监控,导致inode写满导致sendmail和maildrop进程堆积变为僵尸进程,占用内存与系统负载.
还有一个要注意的点就是/var/spool/postfix/maildrop要做定期清理, 这次inode占用很高就是这个目录导致的,文件数量达到了200w,导致inode占满。定期清理这样小文件数量会减少, 降低inode使用率。
2.配置prometheus告警面板与监控
查询语句PromQL语句: inode使用率 > 85%则显示在Grafana面板上
1 | (1-(node_filesystem_files_free/node_filesystem_files)) * 100 > 85 |
告警yaml:
1 | groups: |